
ABAP Quick - Performance Data Filtering
Which statement do you use in ABAP to filter internal tables and is it performant? Read more in this article.

Table of contents
In this article we will look at another performance example and compare different statements and instructions for filtering data from a table.
Introduction
In many situations you can already restrict the data using the WHERE clause of a select statement, but what if the data is already available internally as a table? In this article we will look at the behavior and performance of different combinations and explain the differences.
Preparation
Before we start with the individual scenarios, let's prepare our test data. To do this, we need a structure for a table with a criterion that we will use to filter. In the table there is an identification, some payload in the form of a string and a date that we want to filter on later.
TYPES: BEGIN OF ts_data,
identifier TYPE i,
payload TYPE string,
sdate TYPE d,
END OF ts_data.
TYPES tt_data TYPE STANDARD TABLE OF ts_data WITH EMPTY KEY
WITH NON-UNIQUE SORTED KEY by_date COMPONENTS sdate.
The data is generated randomly. For our test, we create an internal table with 500,000 entries. The identification is filled with the current line number, the text and the date are filled randomly.
DATA(lo_random_date) = NEW zcl_bs_demo_random( id_min = 0
id_max = 180 ).
DATA(lo_random_string) = NEW zcl_bs_demo_random( id_min = 1
id_max = 6 ).
DO c_table_entries TIMES.
INSERT VALUE #( identifier = sy-index
payload = SWITCH #( lo_random_string->rand( )
WHEN 1 THEN `My text is alone`
WHEN 2 THEN `Second entry of this`
WHEN 3 THEN `What you need`
WHEN 4 THEN `The long summer`
WHEN 5 THEN `Advertising your next project`
WHEN 6 THEN `A rainy day` )
sdate = CONV d( cl_abap_context_info=>get_system_date( ) - lo_random_date->rand( ) ) )
INTO TABLE mt_data.
ENDDO.
Finally, we fill in a random date that we want to filter by later.
md_random_filter = cl_abap_context_info=>get_system_date( ) - lo_random_date->rand( ).
Scenarios
The different scenarios and examples are explained below.
Loop with Data
This is a simple loop with LOOP. In the WHERE clause we filter the data records that we want to count and determine the total for RD_RESULT.
LOOP AT mt_data INTO DATA(ls_data) WHERE sdate = md_random_filter.
rd_result += 1.
ENDLOOP.
Loop with Assigning
The second example is quite close to the first with the simple loop, here we use a field symbol in the assignment to see the difference to the inline declaration.
LOOP AT mt_data ASSIGNING FIELD-SYMBOL(<ls_data>) WHERE sdate = md_random_filter.
rd_result += 1.
ENDLOOP.
Loop with key
In the third example we use a loop, but we explicitly use the secondary key. This should increase the performance when accessing the table and be faster than the simple loop.
LOOP AT mt_data ASSIGNING FIELD-SYMBOL(<ls_data>) USING KEY by_date WHERE sdate = md_random_filter.
rd_result += 1.
ENDLOOP.
Filter
In this scenario, we use the FILTER statement to restrict the data sets. Filter always requires a key so that we can work with it effectively. We then use LINES to determine the result.
rd_result = lines( FILTER #( mt_data USING KEY by_date WHERE sdate = md_random_filter ) ).
Reduce
The reduction statement REDUCE is also a new command, with it we can process the data and derive the number of filtered records. When using it, we also use the secondary key of the table.
rd_result = REDUCE #(
INIT ld_count TYPE i
FOR <ls_data> IN mt_data USING KEY by_date WHERE ( sdate = md_random_filter )
NEXT ld_count += 1 ).
FOR
Finally, we use the FOR loop to filter the data sets and use LINES to determine the result. Basically, the same steps are applied as with the FILTER.
rd_result = lines( VALUE tt_data( FOR <ls_data> IN mt_data USING KEY by_date WHERE ( sdate = md_random_filter )
( CORRESPONDING #( <ls_data> ) ) ) ).
Result
The result of the run through 500,000 rows in the internal table:
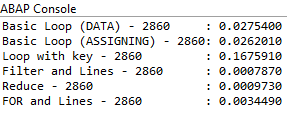
The simple loop, regardless of whether it is with the inline declaration DATA or FIELD-SYMBOLS, is about as fast; there shouldn't be too big a gap here. The performance with the loop and the specification of the secondary key is somewhat surprising; here we would have actually expected the logic to be faster than the simple loop. After some research in the SAP documentation, the first and second accesses seem to run automatically via the optimizer because we specified the secondary key. However, this does not explain the performance for the third variant.
Filter and Reduce won the performance race, the FOR loop with the WHERE condition is a bit slower, but still very fast.
Full example
You can find the full example and the code here. You can find more information about the Random class and the Runtime class in various articles.
CLASS zcl_bs_demo_filtering DEFINITION
PUBLIC FINAL
CREATE PUBLIC.
PUBLIC SECTION.
INTERFACES if_oo_adt_classrun.
TYPES: BEGIN OF ts_data,
identifier TYPE i,
payload TYPE string,
sdate TYPE d,
END OF ts_data.
TYPES tt_data TYPE STANDARD TABLE OF ts_data WITH EMPTY KEY
WITH NON-UNIQUE SORTED KEY by_date COMPONENTS sdate.
PRIVATE SECTION.
CONSTANTS c_table_entries TYPE i VALUE 500000.
DATA mt_data TYPE tt_data.
DATA md_random_filter TYPE d.
METHODS prepare_random_data.
METHODS run_basic_loop_data
RETURNING VALUE(rd_result) TYPE i.
METHODS run_basic_loop_assigning
RETURNING VALUE(rd_result) TYPE i.
METHODS run_loop_with_key
RETURNING VALUE(rd_result) TYPE i.
METHODS run_filter_and_lines
RETURNING VALUE(rd_result) TYPE i.
METHODS run_reduce
RETURNING VALUE(rd_result) TYPE i.
METHODS run_for_lines
RETURNING VALUE(rd_result) TYPE i.
ENDCLASS.
CLASS zcl_bs_demo_filtering IMPLEMENTATION.
METHOD if_oo_adt_classrun~main.
prepare_random_data( ).
DATA(lo_run) = NEW zcl_bs_demo_runtime( ).
DATA(ld_count) = run_basic_loop_data( ).
out->write( |Basic Loop (DATA) - { ld_count } : { lo_run->get_diff( ) }| ).
lo_run = NEW zcl_bs_demo_runtime( ).
ld_count = run_basic_loop_assigning( ).
out->write( |Basic Loop (ASSIGNING) - { ld_count }: { lo_run->get_diff( ) }| ).
lo_run = NEW zcl_bs_demo_runtime( ).
ld_count = run_loop_with_key( ).
out->write( |Loop with key - { ld_count } : { lo_run->get_diff( ) }| ).
lo_run = NEW zcl_bs_demo_runtime( ).
ld_count = run_filter_and_lines( ).
out->write( |Filter and Lines - { ld_count } : { lo_run->get_diff( ) }| ).
lo_run = NEW zcl_bs_demo_runtime( ).
ld_count = run_reduce( ).
out->write( |Reduce - { ld_count } : { lo_run->get_diff( ) }| ).
lo_run = NEW zcl_bs_demo_runtime( ).
ld_count = run_for_lines( ).
out->write( |FOR and Lines - { ld_count } : { lo_run->get_diff( ) }| ).
ENDMETHOD.
METHOD prepare_random_data.
DATA(lo_random_date) = NEW zcl_bs_demo_random( id_min = 0
id_max = 180 ).
DATA(lo_random_string) = NEW zcl_bs_demo_random( id_min = 1
id_max = 6 ).
DO c_table_entries TIMES.
INSERT VALUE #( identifier = sy-index
payload = SWITCH #( lo_random_string->rand( )
WHEN 1 THEN `My text is alone`
WHEN 2 THEN `Second entry of this`
WHEN 3 THEN `What you need`
WHEN 4 THEN `The long summer`
WHEN 5 THEN `Advertising your next project`
WHEN 6 THEN `A rainy day` )
sdate = CONV d( cl_abap_context_info=>get_system_date( ) - lo_random_date->rand( ) ) )
INTO TABLE mt_data.
ENDDO.
md_random_filter = cl_abap_context_info=>get_system_date( ) - lo_random_date->rand( ).
ENDMETHOD.
METHOD run_basic_loop_data.
LOOP AT mt_data INTO DATA(ls_data) WHERE sdate = md_random_filter.
rd_result += 1.
ENDLOOP.
ENDMETHOD.
METHOD run_basic_loop_assigning.
LOOP AT mt_data ASSIGNING FIELD-SYMBOL(<ls_data>) WHERE sdate = md_random_filter.
rd_result += 1.
ENDLOOP.
ENDMETHOD.
METHOD run_loop_with_key.
LOOP AT mt_data ASSIGNING FIELD-SYMBOL(<ls_data>) USING KEY by_date WHERE sdate = md_random_filter.
rd_result += 1.
ENDLOOP.
ENDMETHOD.
METHOD run_filter_and_lines.
rd_result = lines( FILTER #( mt_data USING KEY by_date WHERE sdate = md_random_filter ) ).
ENDMETHOD.
METHOD run_reduce.
rd_result = REDUCE #(
INIT ld_count TYPE i
FOR <ls_data> IN mt_data USING KEY by_date WHERE ( sdate = md_random_filter )
NEXT ld_count += 1 ).
ENDMETHOD.
METHOD run_for_lines.
rd_result = lines( VALUE tt_data( FOR <ls_data> IN mt_data USING KEY by_date WHERE ( sdate = md_random_filter )
( CORRESPONDING #( <ls_data> ) ) ) ).
ENDMETHOD.
ENDCLASS.
Conclusion
When it comes to filtering data sets, you should use the FILTER statement, but your table will then also need a secondary sorted key to benefit from the speed. Overall, you are well advised to use the new statements.


