
ABAP Tipp - Performance Datenfilterung
Welche Anweisung verwendest du in ABAP zur Filterung von internen Tabellen und ist diese performant? In diesem Artikel mehr dazu.

Inhaltsverzeichnis
In diesem Artikel schauen wir uns mal wieder ein Performance-Beispiel an und vergleichen verschiedene Statements und Anweisungen, um Daten aus einer Tabelle zu filtern.
Einleitung
In vielen Situationen kannst du bereits über die WHERE Clause eines Select-Statements die Einschränkung der Daten vornehmen, doch wie sieht es aus, wenn die Daten bereits intern als Tabelle vorliegen? In diesem Artikel werden wir uns das Verhalten und die Performance von verschiedenen Kombinationen anschauen und auf die Unterschiede eingehen.
Vorbereitung
Bevor wir mit den einzelnen Szenarien beginnen, bereiten wir unsere Testdaten einmal vor. Wir benötigen dazu eine Struktur für eine Tabelle mit einem Kriterium, über das wir filtern. In der Tabelle gibt es eine Identifikation, etwas Payload in Form eines Strings und ein Datum, über das wir später filtern wollen.
TYPES: BEGIN OF ts_data,
identifier TYPE i,
payload TYPE string,
sdate TYPE d,
END OF ts_data.
TYPES tt_data TYPE STANDARD TABLE OF ts_data WITH EMPTY KEY
WITH NON-UNIQUE SORTED KEY by_date COMPONENTS sdate.
Die Daten werden zufällig generiert. Für unseren Test legen wir eine interne Tabelle mit 500.000 Einträgen an. Die Identifikation wird mit der aktuellen Zeilennummer befüllt, der Text und das Datum werden zufällig befüllt.
DATA(lo_random_date) = NEW zcl_bs_demo_random( id_min = 0
id_max = 180 ).
DATA(lo_random_string) = NEW zcl_bs_demo_random( id_min = 1
id_max = 6 ).
DO c_table_entries TIMES.
INSERT VALUE #( identifier = sy-index
payload = SWITCH #( lo_random_string->rand( )
WHEN 1 THEN `My text is alone`
WHEN 2 THEN `Second entry of this`
WHEN 3 THEN `What you need`
WHEN 4 THEN `The long summer`
WHEN 5 THEN `Advertising your next project`
WHEN 6 THEN `A rainy day` )
sdate = CONV d( cl_abap_context_info=>get_system_date( ) - lo_random_date->rand( ) ) )
INTO TABLE mt_data.
ENDDO.
Zum Abschluss befüllen wir noch ein zufälliges Datum, über das wir später filtern wollen.
md_random_filter = cl_abap_context_info=>get_system_date( ) - lo_random_date->rand( ).
Szenarien
Im Folgenden werden die verschiedenen Szenarien und Beispiele erklärt.
Loop mit Data
Hierbei handelt es sich um eine einfache Schleife mit LOOP. In der WHERE Clause filtern wir die Datensätze, die wir zählen wollen und ermitteln die Summe für RD_RESULT.
LOOP AT mt_data INTO DATA(ls_data) WHERE sdate = md_random_filter.
rd_result += 1.
ENDLOOP.
Loop mit Assigning
Das zweite Beispiel ist recht nah am ersten mit dem einfachen Loop, hier verwenden wir ein Feldsymbol bei der Zuweisung, um uns den Unterschied zur Inline-Deklaration anzuschauen.
LOOP AT mt_data ASSIGNING FIELD-SYMBOL(<ls_data>) WHERE sdate = md_random_filter.
rd_result += 1.
ENDLOOP.
Loop mit Schlüssel
Im dritten Beispiel verwenden wir einen Loop, dabei verwenden wir aber explizit den sekundären Schlüssel. Das sollte die Performance beim Zugriff auf die Tabelle erhöhen und schneller als der einfache Loop sein.
LOOP AT mt_data ASSIGNING FIELD-SYMBOL(<ls_data>) USING KEY by_date WHERE sdate = md_random_filter.
rd_result += 1.
ENDLOOP.
Filter
In diesem Szenario verwenden wir das FILTER Statement, um die Datensätze einzuschränken. Filter setzt immer einen Schlüssel voraus, damit wir auch effektiv damit arbeiten können. Für das Ergebnis ermitteln wir dann per LINES das Ergebnis.
rd_result = lines( FILTER #( mt_data USING KEY by_date WHERE sdate = md_random_filter ) ).
Reduce
Das Reduzierungs-Statement REDUCE ist ebenfalls ein neuer Befehl, damit können wir die Daten verarbeiten und die Anzahl der gefilterten Datensätze ableiten. Bei der Verwendung nutzen wir ebenfalls den sekundären Schlüssel der Tabelle.
rd_result = REDUCE #(
INIT ld_count TYPE i
FOR <ls_data> IN mt_data USING KEY by_date WHERE ( sdate = md_random_filter )
NEXT ld_count += 1 ).
FOR
Als letztes verwenden wir die FOR Schleife, um die Datensätze zu filtern und per LINES das Ergebnis zu ermitteln. Im Grunde werden die gleichen Schritte wie beim FILTER angewandt.
rd_result = lines( VALUE tt_data( FOR <ls_data> IN mt_data USING KEY by_date WHERE ( sdate = md_random_filter )
( CORRESPONDING #( <ls_data> ) ) ) ).
Ergebnis
Das Ergebnis des Durchlaufs für 500.000 Zeilen in der internen Tabelle:
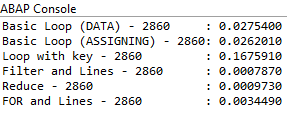
Der einfache Loop, egal ob mit der Inline-Deklaration DATA oder FIELD-SYMBOLS ist in etwa ähnlich schnell, hier sollte es nicht allzu große Abstände geben. Etwas überraschend ist die Performance mit Loop und die Angabe des sekundären Schlüssels, hier hätten wir eigentlich erwartet, dass die Logik schneller als der einfache Loop wäre. Nach etwas Recherche in der SAP Dokumentation scheint der erste und zweite Zugriff automatisch über den Optimizer zu laufen, da wir den sekundären Schlüssel angegeben haben. Das erklärt allerdings nicht die Performance für die dritte Variante.
Filter und Reduce haben das Performance-Rennen gewonnen, die FOR Schleife mit der WHERE Bedingung ist etwas langsamer, aber auch noch sehr schnell.
Vollständiges Beispiel
Das vollständige Beispiel und den Code findest du hier. Mehr Informationen zur Random-Klasse und zur Runtime-Klasse findest du in verschiedenen Artikeln.
CLASS zcl_bs_demo_filtering DEFINITION
PUBLIC FINAL
CREATE PUBLIC.
PUBLIC SECTION.
INTERFACES if_oo_adt_classrun.
TYPES: BEGIN OF ts_data,
identifier TYPE i,
payload TYPE string,
sdate TYPE d,
END OF ts_data.
TYPES tt_data TYPE STANDARD TABLE OF ts_data WITH EMPTY KEY
WITH NON-UNIQUE SORTED KEY by_date COMPONENTS sdate.
PRIVATE SECTION.
CONSTANTS c_table_entries TYPE i VALUE 500000.
DATA mt_data TYPE tt_data.
DATA md_random_filter TYPE d.
METHODS prepare_random_data.
METHODS run_basic_loop_data
RETURNING VALUE(rd_result) TYPE i.
METHODS run_basic_loop_assigning
RETURNING VALUE(rd_result) TYPE i.
METHODS run_loop_with_key
RETURNING VALUE(rd_result) TYPE i.
METHODS run_filter_and_lines
RETURNING VALUE(rd_result) TYPE i.
METHODS run_reduce
RETURNING VALUE(rd_result) TYPE i.
METHODS run_for_lines
RETURNING VALUE(rd_result) TYPE i.
ENDCLASS.
CLASS zcl_bs_demo_filtering IMPLEMENTATION.
METHOD if_oo_adt_classrun~main.
prepare_random_data( ).
DATA(lo_run) = NEW zcl_bs_demo_runtime( ).
DATA(ld_count) = run_basic_loop_data( ).
out->write( |Basic Loop (DATA) - { ld_count } : { lo_run->get_diff( ) }| ).
lo_run = NEW zcl_bs_demo_runtime( ).
ld_count = run_basic_loop_assigning( ).
out->write( |Basic Loop (ASSIGNING) - { ld_count }: { lo_run->get_diff( ) }| ).
lo_run = NEW zcl_bs_demo_runtime( ).
ld_count = run_loop_with_key( ).
out->write( |Loop with key - { ld_count } : { lo_run->get_diff( ) }| ).
lo_run = NEW zcl_bs_demo_runtime( ).
ld_count = run_filter_and_lines( ).
out->write( |Filter and Lines - { ld_count } : { lo_run->get_diff( ) }| ).
lo_run = NEW zcl_bs_demo_runtime( ).
ld_count = run_reduce( ).
out->write( |Reduce - { ld_count } : { lo_run->get_diff( ) }| ).
lo_run = NEW zcl_bs_demo_runtime( ).
ld_count = run_for_lines( ).
out->write( |FOR and Lines - { ld_count } : { lo_run->get_diff( ) }| ).
ENDMETHOD.
METHOD prepare_random_data.
DATA(lo_random_date) = NEW zcl_bs_demo_random( id_min = 0
id_max = 180 ).
DATA(lo_random_string) = NEW zcl_bs_demo_random( id_min = 1
id_max = 6 ).
DO c_table_entries TIMES.
INSERT VALUE #( identifier = sy-index
payload = SWITCH #( lo_random_string->rand( )
WHEN 1 THEN `My text is alone`
WHEN 2 THEN `Second entry of this`
WHEN 3 THEN `What you need`
WHEN 4 THEN `The long summer`
WHEN 5 THEN `Advertising your next project`
WHEN 6 THEN `A rainy day` )
sdate = CONV d( cl_abap_context_info=>get_system_date( ) - lo_random_date->rand( ) ) )
INTO TABLE mt_data.
ENDDO.
md_random_filter = cl_abap_context_info=>get_system_date( ) - lo_random_date->rand( ).
ENDMETHOD.
METHOD run_basic_loop_data.
LOOP AT mt_data INTO DATA(ls_data) WHERE sdate = md_random_filter.
rd_result += 1.
ENDLOOP.
ENDMETHOD.
METHOD run_basic_loop_assigning.
LOOP AT mt_data ASSIGNING FIELD-SYMBOL(<ls_data>) WHERE sdate = md_random_filter.
rd_result += 1.
ENDLOOP.
ENDMETHOD.
METHOD run_loop_with_key.
LOOP AT mt_data ASSIGNING FIELD-SYMBOL(<ls_data>) USING KEY by_date WHERE sdate = md_random_filter.
rd_result += 1.
ENDLOOP.
ENDMETHOD.
METHOD run_filter_and_lines.
rd_result = lines( FILTER #( mt_data USING KEY by_date WHERE sdate = md_random_filter ) ).
ENDMETHOD.
METHOD run_reduce.
rd_result = REDUCE #(
INIT ld_count TYPE i
FOR <ls_data> IN mt_data USING KEY by_date WHERE ( sdate = md_random_filter )
NEXT ld_count += 1 ).
ENDMETHOD.
METHOD run_for_lines.
rd_result = lines( VALUE tt_data( FOR <ls_data> IN mt_data USING KEY by_date WHERE ( sdate = md_random_filter )
( CORRESPONDING #( <ls_data> ) ) ) ).
ENDMETHOD.
ENDCLASS.
Fazit
Wenn es um die Filterung von Datensätzen geht, solltest du das FILTER Statement verwenden, allerdings benötigt deine Tabelle dann auch einen sekundären sortierten Schlüssel, um von der Geschwindigkeit zu profitieren. Insgesamt bist du gut beraten, die neuen Statements zu verwenden.


