
ABAP Cloud - Read XML
How can you read and process XML data relatively easily in ABAP Cloud? Let's look at an example and go through it step by step.

Table of contents
In this article we want to read XML data and convert it into ABAP structures. To do this we will use released classes for ABAP Cloud and in this case we will forego transformations.
Introduction
In addition to JSON, there is also XML as a standard format for interfaces. Therefore we should at least have tools at hand to convert such data.
Format
Let's first look at the basic components of the XML format, how it is structured and which elements are available to us. In the following example we want to discuss some elements of the XML file that are important later for the conversion.

Let's now look at the different points:
- Namespace - With the XML namespace (xmlns) we define the various namespaces used within our XML format. If we do not use a namespace, we do not need a definition of it.
- Attribute - A tag can contain additional properties and attributes that transport further options and content.
- CDATA - If you want to represent free text with unknown content in XML, then you need a CDATA tag. This ensures, among other things, that special characters in the content do not make the XML file corrupt (HTML or other XML content).
- Content - Between a tag you will find the content that can be addressed under this name.
- Tag - A tag always has a beginning and an end, and you will normally come across two variants, one with the content "<TAG>CONTENT</TAG>" and one without the content "<TAG/>". If the tag has a namespace, you will find this in front of the tag, separated by a colon.
Basically, there are still many small details to discover in an XML file or an XML stream, but this should be enough for us for processing.
Parsing content
If we now want to access the content, we can do this via a transformation in the system, for example. To be as flexible as possible, we do this using the shared class CL_SXML_STRING_READER.
Reader
First of all, we need the content (XML) as a string or XString. We can then use this to instantiate the reader. We get the XML as a string using the GET_XML method, in the next step we convert it to XString using the XCO class and then create our reader using the CREATE method.
DATA(xml_string) = get_xml( ).
DATA(binary) = xco_cp=>string( xml_string )->as_xstring( xco_cp_character=>code_page->utf_8 )->value.
DATA(reader) = cl_sxml_string_reader=>create( binary ).
Contents
In the next step, we want to look at the content that the reader would output. To do this, we create a loop and process nodes (tags) one by one. Using the NEXT_NODE method, we load the next node in the XML and the corresponding attributes in the READER object are filled.
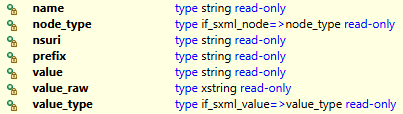
The logic for the output would now look like this. We want to stay in the loop until the last element is reached. We would prepare the attributes accordingly for the output.
WHILE reader->node_type <> if_sxml_node=>co_nt_final.
reader->next_node( ).
DATA(output) = |Namespace: { reader->nsuri }, Name: { reader->name }, XML Type: { reader->xml_type }, Node Type: { reader->node_type }, Prefix: { reader->prefix }|.
output &&= | Value: { reader->value }, Value-Raw: { reader->value_raw }, Value-Type: { reader->value_type }, Offset: { reader->get_byte_offset( ) }|.
out->write( output ).
ENDWHILE.
The same node is called 3 times, once to open it, to read the value and once to close it. We can check which element it is using the NODE_TYPE attribute and the corresponding constants in the IF_SXML_NODE interface. The result of our first run would therefore look like this:

So what information do we find now? You will find the most important fields and contents here.
- NSURI - Namespace URI, i.e. the URL to the namespace from the header
- NAME - Name of the current tag
- NODE_TYPE - Type of the current node (constants from the interface IF_SXML_NODE)
- VALUE - Content that is between the tags
- PREFIX - If the tag has a namespace, you will find the front part here
Attributes
But we are still missing one thing. We currently have no information about the contents of the attributes that are attached to the various tags. There are currently two methods for this. If we do not know which attributes are present, we can determine this quite generically using the NEXT_ATTRIBUTE method. The NODE_TYPE is set to attribute and we can check further here.
reader->next_attribute( ).
WHILE reader->node_type = if_sxml_node=>co_nt_attribute.
DATA(output) = |Namespace: { reader->nsuri }, Name: { reader->name }, XML Type: { reader->xml_type }, Node Type: { reader->node_type }, Prefix: { reader->prefix }|.
output &&= | Value: { reader->value }, Value-Raw: { reader->value_raw }, Value-Type: { reader->value_type }, Offset: { reader->get_byte_offset( ) }|.
out->write( output ).
reader->next_attribute( ).
ENDWHILE.
Finally, we now have all the attributes together and can look at the result and the various fields in the ABAP console.

With the second method, we know the attributes and the structure of the XML file. In this case, for example, we can read specific values using the GET_ATTRIBUTE_VALUE method and do not have to process all the data if we may not need it.
Result
Now that you know the theory and a few small examples, we can start actually parsing the XML shown above. To do this, we define an internal ABAP structure to map the XML file.
TYPES: BEGIN OF people,
height TYPE c LENGTH 9,
name TYPE string,
END OF people.
TYPES peoples TYPE STANDARD TABLE OF people WITH EMPTY KEY.
TYPES: BEGIN OF file,
head_key TYPE c LENGTH 10,
head_description TYPE string,
title TYPE string,
description TYPE string,
desc_length TYPE i,
desc_space TYPE c LENGTH 20,
tags TYPE string,
peoples TYPE peoples,
END OF file.
Unfortunately, the combined reading of tags and attributes does not work properly and the attributes in the READER object are not set properly, so we have to proceed a little differently here to get the right result. We should note the following points:
- The content between the tags is at the level of NODE_TYPE = IF_SXML_NODE=>CO_NT_VALUE (value 4)
- The attributes are at the level of NODE_TYPE = IF_SXML_NODE=>CO_NT_ELEMENT_OPEN (value 1)
- The content on the opening tag is always from the last tag during the run (see example screenshot of reading the nodes above).
In this case we use a different method on the reader and have the node returned as its own object. Basically, the attributes in the reader object are not changed when we read the various attributes on the generated object.
DATA(node) = reader->read_next_node( ).
Then we proceed as follows: We note the last tag opened in order to then determine all values for NODE_TYPE = IF_SXML_NODE=>CO_NT_VALUE (value 4). We receive the current content of the tag via the READER and the attributes via the open node, so we can fill our structure with the content.
DO.
DATA(node) = reader->read_next_node( ).
IF reader->node_type = if_sxml_node=>co_nt_final.
EXIT.
ENDIF.
IF reader->node_type = if_sxml_node=>co_nt_element_open.
last_open_tag = CAST if_sxml_open_element( node ).
CASE to_upper( reader->name ).
WHEN 'MYROOT'.
result-head_key = last_open_tag->get_attribute_value( name = 'key' )->get_value( ).
result-head_description = last_open_tag->get_attribute_value( name = 'description' )->get_value( ).
ENDCASE.
ENDIF.
IF reader->node_type <> if_sxml_node=>co_nt_value.
CONTINUE.
ENDIF.
CASE to_upper( reader->name ).
WHEN 'DESCRIPTION'.
result-description = reader->value.
result-desc_length = last_open_tag->get_attribute_value( name = 'length' )->get_value( ).
result-desc_space = last_open_tag->get_attribute_value( name = 'space' )->get_value( ).
WHEN 'ITEM'.
INSERT INITIAL LINE INTO TABLE result-peoples REFERENCE INTO person.
person->height = last_open_tag->get_attribute_value( name = 'height' )->get_value( ).
person->name = reader->value.
WHEN OTHERS.
ASSIGN COMPONENT to_upper( reader->name ) OF STRUCTURE result TO FIELD-SYMBOL(<line>).
IF sy-subrc = 0.
<line> = reader->value.
ENDIF.
ENDCASE.
ENDDO.
Unfortunately, a case does not work with this, and that is the case with all tags that have no value as content, but other tags. In this case, that would be MYROOT and TABLE. To do this, we must define a special case that goes into the IF statement to remember the last open sentence. Then we can also read in these attributes and get the following result:
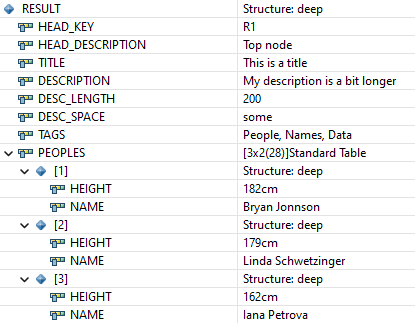
Complete example
Here you can find the complete class with the examples shown. The XML stream is in the class, so you can recreate the example directly.
CLASS zcl_bs_demo_xml_read DEFINITION
PUBLIC FINAL
CREATE PUBLIC.
PUBLIC SECTION.
INTERFACES if_oo_adt_classrun.
PRIVATE SECTION.
TYPES: BEGIN OF people,
height TYPE c LENGTH 9,
name TYPE string,
END OF people.
TYPES peoples TYPE STANDARD TABLE OF people WITH EMPTY KEY.
TYPES: BEGIN OF file,
head_key TYPE c LENGTH 10,
head_description TYPE string,
title TYPE string,
description TYPE string,
desc_length TYPE i,
desc_space TYPE c LENGTH 20,
tags TYPE string,
peoples TYPE peoples,
END OF file.
METHODS read_all_nodes_and_write
IMPORTING !out TYPE REF TO if_oo_adt_classrun_out.
METHODS get_xml
RETURNING VALUE(result) TYPE string.
METHODS read_attributes_from_tags
IMPORTING !out TYPE REF TO if_oo_adt_classrun_out.
METHODS parse_document
IMPORTING !out TYPE REF TO if_oo_adt_classrun_out
RETURNING VALUE(result) TYPE file.
ENDCLASS.
CLASS zcl_bs_demo_xml_read IMPLEMENTATION.
METHOD get_xml.
RETURN |<?xml version="1.0" encoding="utf-8"?>| &
|<swh:myroot xmlns:swh="http://software-heroes/swh" key="R1" description="Top node">| &
| <swh:title>This is a title</swh:title>| &
| <swh:description length="200" space="some"><![CDATA[My description is a bit longer]]></swh:description>| &
| <table>| &
| <item height="182cm">Bryan Jonnson</item>| &
| <item height="179cm">Linda Schwetzinger</item>| &
| <item height="162cm">Iana Petrova</item>| &
| </table>| &
| <swh:tags>People, Names, Data</swh:tags>| &
|</swh:myroot>|.
ENDMETHOD.
METHOD if_oo_adt_classrun~main.
read_all_nodes_and_write( out ).
read_attributes_from_tags( out ).
parse_document( out ).
ENDMETHOD.
METHOD read_all_nodes_and_write.
DATA(xml_string) = get_xml( ).
DATA(binary) = xco_cp=>string( xml_string )->as_xstring( xco_cp_character=>code_page->utf_8 )->value.
DATA(reader) = cl_sxml_string_reader=>create( binary ).
WHILE reader->node_type <> if_sxml_node=>co_nt_final.
reader->next_node( ).
DATA(output) = |Namespace: { reader->nsuri }, Name: { reader->name }, XML Type: { reader->xml_type }, Node Type: { reader->node_type }, Prefix: { reader->prefix }|.
output &&= | Value: { reader->value }, Value-Raw: { reader->value_raw }, Value-Type: { reader->value_type }, Offset: { reader->get_byte_offset( ) }|.
out->write( output ).
ENDWHILE.
ENDMETHOD.
METHOD read_attributes_from_tags.
DATA(xml_string) = get_xml( ).
DATA(binary) = xco_cp=>string( xml_string )->as_xstring( xco_cp_character=>code_page->utf_8 )->value.
DATA(reader) = cl_sxml_string_reader=>create( binary ).
DATA(finished) = abap_false.
WHILE finished = abap_false.
reader->next_node( ).
IF reader->node_type = if_sxml_node=>co_nt_final.
finished = abap_true.
ENDIF.
IF reader->node_type <> if_sxml_node=>co_nt_element_open.
CONTINUE.
ENDIF.
reader->next_attribute( ).
WHILE reader->node_type = if_sxml_node=>co_nt_attribute.
DATA(output) = |Namespace: { reader->nsuri }, Name: { reader->name }, XML Type: { reader->xml_type }, Node Type: { reader->node_type }, Prefix: { reader->prefix }|.
output &&= | Value: { reader->value }, Value-Raw: { reader->value_raw }, Value-Type: { reader->value_type }, Offset: { reader->get_byte_offset( ) }|.
out->write( output ).
reader->next_attribute( ).
ENDWHILE.
ENDWHILE.
ENDMETHOD.
METHOD parse_document.
DATA last_open_tag TYPE REF TO if_sxml_open_element.
DATA person TYPE REF TO zcl_bs_demo_xml_read=>people.
DATA(xml_string) = get_xml( ).
DATA(binary) = xco_cp=>string( xml_string )->as_xstring( xco_cp_character=>code_page->utf_8 )->value.
DATA(reader) = cl_sxml_string_reader=>create( binary ).
DO.
DATA(node) = reader->read_next_node( ).
IF reader->node_type = if_sxml_node=>co_nt_final.
EXIT.
ENDIF.
IF reader->node_type = if_sxml_node=>co_nt_element_open.
last_open_tag = CAST if_sxml_open_element( node ).
CASE to_upper( reader->name ).
WHEN 'MYROOT'.
result-head_key = last_open_tag->get_attribute_value( name = 'key' )->get_value( ).
result-head_description = last_open_tag->get_attribute_value( name = 'description' )->get_value( ).
ENDCASE.
ENDIF.
IF reader->node_type <> if_sxml_node=>co_nt_value.
CONTINUE.
ENDIF.
CASE to_upper( reader->name ).
WHEN 'DESCRIPTION'.
result-description = reader->value.
result-desc_length = last_open_tag->get_attribute_value( name = 'length' )->get_value( ).
result-desc_space = last_open_tag->get_attribute_value( name = 'space' )->get_value( ).
WHEN 'ITEM'.
INSERT INITIAL LINE INTO TABLE result-peoples REFERENCE INTO person.
person->height = last_open_tag->get_attribute_value( name = 'height' )->get_value( ).
person->name = reader->value.
WHEN OTHERS.
ASSIGN COMPONENT to_upper( reader->name ) OF STRUCTURE result TO FIELD-SYMBOL(<line>).
IF sy-subrc = 0.
<line> = reader->value.
ENDIF.
ENDCASE.
ENDDO.
ENDMETHOD.
ENDCLASS.
Conclusion
Reading XML streams can be implemented relatively easily, but it becomes a little more difficult with mixed structures with attributes and tags. In your research, you will probably find other examples that work differently. You should find the best way for you here.


