ABAP Cloud - XML lesen
Wie kannst du in ABAP Cloud relativ einfach XML Daten lesen und verarbeiten? Dazu schauen wir uns ein Beispiel an und gehen das Schritt für Schritt durch.

Inhaltsverzeichnis
In diesem Artikel möchten wir XML Daten lesen und in ABAP Strukturen überführen. Dazu verwenden wir freigegebene Klassen für ABAP Cloud und verzichten in diesem Fall auf Transformationen.
Einleitung
Neben JSON gibt es noch XML als Standardformat bei Schnittstellen. Daher sollten wir zumindest Hilfsmittel zur Hand haben, um solche Daten zu konvertieren.
Format
Schauen wir uns das XML Format erst einmal in den Grundbestandteilen an, wie es aufgebaut ist und welche Elemente uns zur Verfügung stehen. Im folgenden Beispiel wollen wir einige Elemente der XML Datei besprechen, die später für die Konvertierung wichtig sind.

Schauen wir uns nun die verschiedenen Punkte einmal an:
- Namespace - Mit dem XML Namespace (xmlns) definieren wir die verschiedenen verwendeten Namespaces innerhalb unser XML Formats. verwenden wir keinen Namespace, benötigen wir auch keine Definition davon.
- Attribut - Ein Tag kann zusätzliche Eigenschaften und Attribute enthalten, die weitere Möglichkeiten und Inhalte transportieren.
- CDATA - Möchtest du einen freien Text mit unbekannten Inhalten in XML darstellen, dann benötigst du ein CDATA Tag. Dieses stellt unter anderem sicher, das Sonderzeichen im Inhalt nicht die XML Datei fehlerhaft machen (HTML oder anderer XML Inhalt).
- Inhalt - Zwischen einem Tag findest du den Inhalt, der unter diesem Namen angesprochen werden kann.
- Tag - Ein Tag besitzt immer einen Anfang und ein Ende, dabei wirst du normalerweise auf zwei Varianten treffen, einmal mit Inhalt "<TAG>INHALT</TAG>" und einmal ohne Inhalt "<TAG/>". Hat das Tag einen Namespace, findest du diesen vor dem Tag mit einem Doppelpunkt getrennt.
Grundsätzlich gibt es noch viele kleine Details in einer XML Datei oder einem XML Stream zu entdecken, uns sollte das aber erst einmal für die Verarbeitung reichen.
Inhalte parsen
Wollen wir nun auf die Inhalte zugreifen, können wir das zum Beispiel über eine Transformation im System machen. Damit wir aber so flexibel wie möglich sind, machen wir das über die freigegebene Klasse CL_SXML_STRING_READER.
Reader
Dazu benötigen wir zuerst einmal den Inhalt (XML) als String oder XString. Über diesen können wir dann den Reader instanziieren. Über die Methode GET_XML bekommen wir das XML als String, im nächsten Schritt konvertieren wir es über die XCO Klasse nach XString und erzeugen dann über die CREATE Methode unseren Reader.
DATA(xml_string) = get_xml( ).
DATA(binary) = xco_cp=>string( xml_string )->as_xstring( xco_cp_character=>code_page->utf_8 )->value.
DATA(reader) = cl_sxml_string_reader=>create( binary ).
Inhalte
Im nächsten Schritt wollen wir uns die Inhalte anschauen, die der Reader ausgeben würde. Dazu erstellen wir eine Schleife und arbeiten Knoten (Tag) für Knoten ab. Über die Methode NEXT_NODE laden wir den nächsten Knoten im XML und es werden die entsprechenden Attribute im READER Objekt befüllt.
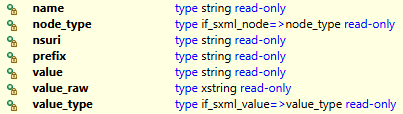
Die Logik zur Ausgabe würden nun wie folgt aussehen. Dabei wollen wir so lange in der Schleife bleiben, bis das letzte Element erreicht ist. Die Attribute würden wir entsprechend für die Ausgabe aufbereiten.
WHILE reader->node_type <> if_sxml_node=>co_nt_final.
reader->next_node( ).
DATA(output) = |Namespace: { reader->nsuri }, Name: { reader->name }, XML Type: { reader->xml_type }, Node Type: { reader->node_type }, Prefix: { reader->prefix }|.
output &&= | Value: { reader->value }, Value-Raw: { reader->value_raw }, Value-Type: { reader->value_type }, Offset: { reader->get_byte_offset( ) }|.
out->write( output ).
ENDWHILE.
Der gleiche Knoten wird jeweils 3 mal aufgerufen, einmal zum Öffnen, um den Wert zu Lesen und einmal zum Abschluss. Über das Attribut NODE_TYPE und die entsprechenden Konstanten im Interface IF_SXML_NODE können wir überprüfen, um welches Element es sich handelt. Das Ergebnis unseren ersten Laufs würde daher wie folgt aussehen:

Welche Informationen finden wir nun also? Dabei findest du hier die wichtigsten Felder und Inhalte.
- NSURI - Namespace URI, also die URL zum Namespace aus dem Kopf
- NAME - Name des aktuellen Tags
- NODE_TYPE - Typ des aktuellen Knotens (Konstanten aus dem Interface IF_SXML_NODE)
- VALUE - Inhalt der zwischen den Tags steht
- PREFIX - Besitzt das Tag einen Namespace, findest du hier den vorderen Teil
Attribute
Eine Sache würde uns aber noch fehlen. Aktuell haben wir keine Information über die Inhalte der Attribute, die an den verschiedenen Tags angehangen sind. Dazu gibt es aktuell zwei Methoden, wissen wir nicht welche Attribute vorhanden sind, können wir dies recht generische ermitteln über die Methode NEXT_ATTRIBUTE. Dabei wird der NODE_TYPE auf Attribut gestellt und wir können hier weiter prüfen.
reader->next_attribute( ).
WHILE reader->node_type = if_sxml_node=>co_nt_attribute.
DATA(output) = |Namespace: { reader->nsuri }, Name: { reader->name }, XML Type: { reader->xml_type }, Node Type: { reader->node_type }, Prefix: { reader->prefix }|.
output &&= | Value: { reader->value }, Value-Raw: { reader->value_raw }, Value-Type: { reader->value_type }, Offset: { reader->get_byte_offset( ) }|.
out->write( output ).
reader->next_attribute( ).
ENDWHILE.
Zum Abschluss hätten wir nun alle Attribute zusammen und können uns das Ergebnis und die verschiedenen Felder in der ABAP Konsole anschauen.

Bei der zweiten Methode kennen wir die Attribute und die Struktur der XML Datei. In diesem Fall können wir zum Beispiel spezifische Werte über die Methode GET_ATTRIBUTE_VALUE einlesen und müssen nicht alle Daten verarbeiten, wenn wir diese vielleicht nicht brauchen.
Ergebnis
Da du nun so weit die Theorie und einige kleine Beispiele dazu kennst, können wir ans eigentliche Parsen des oben gezeigten XML gehen. Dazu definieren wir uns eine interne ABAP Struktur, um das XML File abzubilden.
TYPES: BEGIN OF people,
height TYPE c LENGTH 9,
name TYPE string,
END OF people.
TYPES peoples TYPE STANDARD TABLE OF people WITH EMPTY KEY.
TYPES: BEGIN OF file,
head_key TYPE c LENGTH 10,
head_description TYPE string,
title TYPE string,
description TYPE string,
desc_length TYPE i,
desc_space TYPE c LENGTH 20,
tags TYPE string,
peoples TYPE peoples,
END OF file.
Beim kombinierten Lesen von Tags und Attributen kommt es leider zu einem nicht sauberen Verhalten und die Attribute im READER Objekt werden nicht sauber gesetzt, deshalb müssen wir hier etwas anders vorgehen, um ein richtiges Ergebnis zu erhalten. Die folgenden Punkte sollten wir beachten:
- Der Inhalt zwischen den Tags befindet sich auf Ebene des NODE_TYPE = IF_SXML_NODE=>CO_NT_VALUE (Wert 4)
- Die Attribute befinden sich auf Ebene des NODE_TYPE = IF_SXML_NODE=>CO_NT_ELEMENT_OPEN (Wert 1)
- Der Inhalt auf dem öffnenden Tag ist während des Durchlaufs immer vom letzten Tag (siehe Beispiel Screenshot vom Lesen der Knoten oben).
In diesem Fall verwenden wir eine andere Methode auf dem Reader und lassen uns den Knoten (die Node) als eigenes Objekt zurückgeben. Grundsätzlich werden die Attribute in dem Reader Objekt dann nicht verändert, wenn wir auf dem erzeugten Objekt die verschiedenen Attribute nachlesen.
DATA(node) = reader->read_next_node( ).
Dann gehen wir wie folgt vor: Wir merken uns das zuletzt geöffnete Tag, um dann beim NODE_TYPE = IF_SXML_NODE=>CO_NT_VALUE (Wert 4) alle Werte zu ermitteln. Über den READER erhalten wir den aktuellen Inhalt des Tags und über den offenen Knoten die Attribute dazu, damit können wir unsere Struktur mit den Inhalten befüllen.
DO.
DATA(node) = reader->read_next_node( ).
IF reader->node_type = if_sxml_node=>co_nt_final.
EXIT.
ENDIF.
IF reader->node_type = if_sxml_node=>co_nt_element_open.
last_open_tag = CAST if_sxml_open_element( node ).
CASE to_upper( reader->name ).
WHEN 'MYROOT'.
result-head_key = last_open_tag->get_attribute_value( name = 'key' )->get_value( ).
result-head_description = last_open_tag->get_attribute_value( name = 'description' )->get_value( ).
ENDCASE.
ENDIF.
IF reader->node_type <> if_sxml_node=>co_nt_value.
CONTINUE.
ENDIF.
CASE to_upper( reader->name ).
WHEN 'DESCRIPTION'.
result-description = reader->value.
result-desc_length = last_open_tag->get_attribute_value( name = 'length' )->get_value( ).
result-desc_space = last_open_tag->get_attribute_value( name = 'space' )->get_value( ).
WHEN 'ITEM'.
INSERT INITIAL LINE INTO TABLE result-peoples REFERENCE INTO person.
person->height = last_open_tag->get_attribute_value( name = 'height' )->get_value( ).
person->name = reader->value.
WHEN OTHERS.
ASSIGN COMPONENT to_upper( reader->name ) OF STRUCTURE result TO FIELD-SYMBOL(<line>).
IF sy-subrc = 0.
<line> = reader->value.
ENDIF.
ENDCASE.
ENDDO.
Ein Case funktioniert damit leider nicht, und zwar bei allen Tags die als Inhalt keinen Wert haben, sondern andere Tags. In diesem Fall wäre das MYROOT und TABLE. Dazu müssen wir dann einen Sonderfall definieren, der in das IF Statement zum Merken des letzten offenen Satzes kommt. Dann können wir auch diese Attribute einlesen und erhalten das folgende Ergebnis:
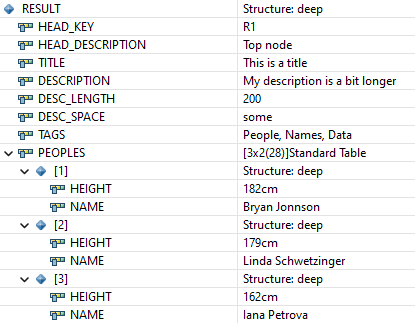
Vollständiges Beispiel
Hier findest du die vollständige Klasse mit den gezeigten Beispielen. Der XML Stream befindet sich in der Klasse, sodass du das Beispiel direkt nachstellen kannst.
CLASS zcl_bs_demo_xml_read DEFINITION
PUBLIC FINAL
CREATE PUBLIC.
PUBLIC SECTION.
INTERFACES if_oo_adt_classrun.
PRIVATE SECTION.
TYPES: BEGIN OF people,
height TYPE c LENGTH 9,
name TYPE string,
END OF people.
TYPES peoples TYPE STANDARD TABLE OF people WITH EMPTY KEY.
TYPES: BEGIN OF file,
head_key TYPE c LENGTH 10,
head_description TYPE string,
title TYPE string,
description TYPE string,
desc_length TYPE i,
desc_space TYPE c LENGTH 20,
tags TYPE string,
peoples TYPE peoples,
END OF file.
METHODS read_all_nodes_and_write
IMPORTING !out TYPE REF TO if_oo_adt_classrun_out.
METHODS get_xml
RETURNING VALUE(result) TYPE string.
METHODS read_attributes_from_tags
IMPORTING !out TYPE REF TO if_oo_adt_classrun_out.
METHODS parse_document
IMPORTING !out TYPE REF TO if_oo_adt_classrun_out
RETURNING VALUE(result) TYPE file.
ENDCLASS.
CLASS zcl_bs_demo_xml_read IMPLEMENTATION.
METHOD get_xml.
RETURN |<?xml version="1.0" encoding="utf-8"?>| &
|<swh:myroot xmlns:swh="http://software-heroes/swh" key="R1" description="Top node">| &
| <swh:title>This is a title</swh:title>| &
| <swh:description length="200" space="some"><![CDATA[My description is a bit longer]]></swh:description>| &
| <table>| &
| <item height="182cm">Bryan Jonnson</item>| &
| <item height="179cm">Linda Schwetzinger</item>| &
| <item height="162cm">Iana Petrova</item>| &
| </table>| &
| <swh:tags>People, Names, Data</swh:tags>| &
|</swh:myroot>|.
ENDMETHOD.
METHOD if_oo_adt_classrun~main.
read_all_nodes_and_write( out ).
read_attributes_from_tags( out ).
parse_document( out ).
ENDMETHOD.
METHOD read_all_nodes_and_write.
DATA(xml_string) = get_xml( ).
DATA(binary) = xco_cp=>string( xml_string )->as_xstring( xco_cp_character=>code_page->utf_8 )->value.
DATA(reader) = cl_sxml_string_reader=>create( binary ).
WHILE reader->node_type <> if_sxml_node=>co_nt_final.
reader->next_node( ).
DATA(output) = |Namespace: { reader->nsuri }, Name: { reader->name }, XML Type: { reader->xml_type }, Node Type: { reader->node_type }, Prefix: { reader->prefix }|.
output &&= | Value: { reader->value }, Value-Raw: { reader->value_raw }, Value-Type: { reader->value_type }, Offset: { reader->get_byte_offset( ) }|.
out->write( output ).
ENDWHILE.
ENDMETHOD.
METHOD read_attributes_from_tags.
DATA(xml_string) = get_xml( ).
DATA(binary) = xco_cp=>string( xml_string )->as_xstring( xco_cp_character=>code_page->utf_8 )->value.
DATA(reader) = cl_sxml_string_reader=>create( binary ).
DATA(finished) = abap_false.
WHILE finished = abap_false.
reader->next_node( ).
IF reader->node_type = if_sxml_node=>co_nt_final.
finished = abap_true.
ENDIF.
IF reader->node_type <> if_sxml_node=>co_nt_element_open.
CONTINUE.
ENDIF.
reader->next_attribute( ).
WHILE reader->node_type = if_sxml_node=>co_nt_attribute.
DATA(output) = |Namespace: { reader->nsuri }, Name: { reader->name }, XML Type: { reader->xml_type }, Node Type: { reader->node_type }, Prefix: { reader->prefix }|.
output &&= | Value: { reader->value }, Value-Raw: { reader->value_raw }, Value-Type: { reader->value_type }, Offset: { reader->get_byte_offset( ) }|.
out->write( output ).
reader->next_attribute( ).
ENDWHILE.
ENDWHILE.
ENDMETHOD.
METHOD parse_document.
DATA last_open_tag TYPE REF TO if_sxml_open_element.
DATA person TYPE REF TO zcl_bs_demo_xml_read=>people.
DATA(xml_string) = get_xml( ).
DATA(binary) = xco_cp=>string( xml_string )->as_xstring( xco_cp_character=>code_page->utf_8 )->value.
DATA(reader) = cl_sxml_string_reader=>create( binary ).
DO.
DATA(node) = reader->read_next_node( ).
IF reader->node_type = if_sxml_node=>co_nt_final.
EXIT.
ENDIF.
IF reader->node_type = if_sxml_node=>co_nt_element_open.
last_open_tag = CAST if_sxml_open_element( node ).
CASE to_upper( reader->name ).
WHEN 'MYROOT'.
result-head_key = last_open_tag->get_attribute_value( name = 'key' )->get_value( ).
result-head_description = last_open_tag->get_attribute_value( name = 'description' )->get_value( ).
ENDCASE.
ENDIF.
IF reader->node_type <> if_sxml_node=>co_nt_value.
CONTINUE.
ENDIF.
CASE to_upper( reader->name ).
WHEN 'DESCRIPTION'.
result-description = reader->value.
result-desc_length = last_open_tag->get_attribute_value( name = 'length' )->get_value( ).
result-desc_space = last_open_tag->get_attribute_value( name = 'space' )->get_value( ).
WHEN 'ITEM'.
INSERT INITIAL LINE INTO TABLE result-peoples REFERENCE INTO person.
person->height = last_open_tag->get_attribute_value( name = 'height' )->get_value( ).
person->name = reader->value.
WHEN OTHERS.
ASSIGN COMPONENT to_upper( reader->name ) OF STRUCTURE result TO FIELD-SYMBOL(<line>).
IF sy-subrc = 0.
<line> = reader->value.
ENDIF.
ENDCASE.
ENDDO.
ENDMETHOD.
ENDCLASS.
Fazit
Das Lesen von XML Streams kann relativ leicht umgesetzt werden, etwas schwieriger wird es bei gemischten Strukturen mit Attributen und Tags. Hier wirst du bei deiner Recherche wahrscheinlich auch andere Beispiele finden, die wiederrum anders arbeiten. Hier solltest du für dich den besten Weg finden.