
ABAP in der Praxis - Datenmenge zusammenführen
Wir führen wir zwei unterschiedliche Datenmengen in ABAP zusammen, vor allem im Hinblick auf das Moderne ABAP? Eine praktische Aufgabe zum Thema.

Inhaltsverzeichnis
In einem Blog in der Vergangenheit hatten wir über den INSERT geschrieben und wie er den APPEND ablösen wird, da er flexibler ist und sich in allen Situationen einsetzen lässt. In diesem Artikel schauen wir uns ein praktisches Beispiel an.
Einleitung
Worum geht es in diesem Beispiel? Hier geht es um eine Aufgabe zwei Datenmengen in eine Tabelle zu überführen und dabei auf Duplikate zu achten, da es eine sortierte Zieltabelle ist. Dabei wollen wir nur wenig Logik einsetzen und effektiv im Modernen ABAP arbeiten.
Vorbereitung
Zuerst einmal benötigen wir zwei Typen, die wir miteinander verschmelzen wollen, die aber nicht komplett gleich sind. Beide Strukturen besitzen eine einheitliche Identifikation (IDENT) und einige Flags, die in beiden Strukturen existieren. Ein Tabellentyp ist eine sortierte Tabelle mit Schlüssel, die andere eine Standard-Tabelle.
TYPES: BEGIN OF ts_unsorted,
ident TYPE i,
test1 TYPE abap_bool,
test2 TYPE abap_bool,
test3 TYPE abap_bool,
test4 TYPE abap_bool,
END OF ts_unsorted.
TYPES tt_unsorted TYPE STANDARD TABLE OF ts_unsorted WITH EMPTY KEY.
TYPES: BEGIN OF ts_sorted,
ident TYPE i,
test2 TYPE abap_bool,
test4 TYPE abap_bool,
test6 TYPE abap_bool,
END OF ts_sorted.
TYPES tt_sorted TYPE SORTED TABLE OF ts_sorted WITH UNIQUE KEY ident.
Im nächsten Schritt befüllen wir die beiden Tabellen mit zufälligen Datensätzen, um einige Daten zu haben. In diesem Fall gibt es in beiden Tabellen den Eintrag 3, also ein Duplikat.
DATA(lt_unsorted) = VALUE tt_unsorted(
( ident = 2 test1 = abap_true test2 = abap_true test3 = abap_false test4 = abap_true )
( ident = 3 test1 = abap_false test2 = abap_true test3 = abap_true test4 = abap_false )
( ident = 7 test1 = abap_true test2 = abap_false test3 = abap_true test4 = abap_true ) ).
DATA(lt_sorted) = VALUE tt_sorted( ( ident = 1 test2 = abap_false test4 = abap_true test6 = abap_false )
( ident = 3 test2 = abap_true test4 = abap_true test6 = abap_true )
( ident = 5 test2 = abap_false test4 = abap_false test6 = abap_true ) ).
Aufgabe
Die Aufgabe besteht nun die beiden Tabellen zusammenzuführen. Dabei haben wir bereits die sortierte Tabelle in das RESULT übernommen und die Daten aus der Standardtabelle müssen noch übernommen werden. Wie würdest du vorgehen? Hier findest du noch einmal die vollständige Klasse, um sie bei dir im System zu übernehmen.
CLASS zcl_bs_demo_puzzle_02 DEFINITION
PUBLIC FINAL
CREATE PUBLIC.
PUBLIC SECTION.
INTERFACES if_oo_adt_classrun.
TYPES: BEGIN OF ts_unsorted,
ident TYPE i,
test1 TYPE abap_bool,
test2 TYPE abap_bool,
test3 TYPE abap_bool,
test4 TYPE abap_bool,
END OF ts_unsorted.
TYPES tt_unsorted TYPE STANDARD TABLE OF ts_unsorted WITH EMPTY KEY.
TYPES: BEGIN OF ts_sorted,
ident TYPE i,
test2 TYPE abap_bool,
test4 TYPE abap_bool,
test6 TYPE abap_bool,
END OF ts_sorted.
TYPES tt_sorted TYPE SORTED TABLE OF ts_sorted WITH UNIQUE KEY ident.
PRIVATE SECTION.
METHODS insert_into_sorted_data
IMPORTING it_unsorted TYPE tt_unsorted
it_sorted TYPE tt_sorted
RETURNING VALUE(rt_result) TYPE tt_sorted.
ENDCLASS.
CLASS zcl_bs_demo_puzzle_02 IMPLEMENTATION.
METHOD if_oo_adt_classrun~main.
DATA(lt_unsorted) = VALUE tt_unsorted(
( ident = 2 test1 = abap_true test2 = abap_true test3 = abap_false test4 = abap_true )
( ident = 3 test1 = abap_false test2 = abap_true test3 = abap_true test4 = abap_false )
( ident = 7 test1 = abap_true test2 = abap_false test3 = abap_true test4 = abap_true ) ).
DATA(lt_sorted) = VALUE tt_sorted( ( ident = 1 test2 = abap_false test4 = abap_true test6 = abap_false )
( ident = 3 test2 = abap_true test4 = abap_true test6 = abap_true )
( ident = 5 test2 = abap_false test4 = abap_false test6 = abap_true ) ).
out->write( insert_into_sorted_data( it_unsorted = lt_unsorted
it_sorted = lt_sorted ) ).
ENDMETHOD.
METHOD insert_into_sorted_data.
rt_result = it_sorted.
" Solution here
ENDMETHOD.
ENDCLASS.
Hinweis: Im nächsten Abschnitt werden wir auf die Lösung eingehen, wenn du die Aufgabe erst einmal selbstständig machen möchtest, solltest du hier pausieren.
Lösung
Die Lösung unterteilen wir in zwei Vorschläge. Dabei werden wir die Übernahme in einem Schritt mit möglichst einem Statement durchführen.
Vorschlag 1 - Insert
Im ersten Schritt versuchen wir es mit einem einfachen Insert, um die Daten von einer Tabelle in die Zieltabelle zu übernehmen.
- Dabei verwenden wir den CORRESPONDING, um das Mapping auf die unterschiedliche Zielstruktur hinzubekommen.
- Den Typ müssen wir angeben, da wir sonst die Fehlermeldung vom Compiler bekommen, dass der Typ nicht abgeleitet werden kann.
- Über den INSERT wollen wir alle Zeilen unserer Tabelle korrekt in die Zieltabelle einfügen.
INSERT LINES OF CORRESPONDING tt_sorted( it_unsorted ) INTO TABLE rt_result.
Diese Lösung funktioniert recht gut, allerdings erhalten wir bei doppelten Schlüsseln einen entsprechenden Abbruch. Der Insert verarbeitet die Duplikate nicht sauber und versucht diese trotzdem in unsere Zieltabelle zu übernehmen.
Vorschlag 2 - Corresponding
Für die zweite Lösung verwenden wir den Corresponding ohne einen zusätzlichen Befehl. Wahrscheinlich kommt dir die erste Frage in den Sinn: Wieso diesen Befehl für die Übernahme von Datensätzen?
- Wir nutzen den BASE Zusatz des CORRESPONDING, damit übernehmen wir im ersten Schritt die Datensätze aus dem Ergebnis in unsere neue Datenmenge.
- Dann übernehmen wir die Datensätze aus unserer unsortierten Tabelle.
- Damit wir keine Fehlermeldung erhalten, verwenden wir weiterhin den Zusatz DISCARD DUPLICATES, um Duplikate zu ignorieren.
rt_result = CORRESPONDING #( BASE ( rt_result ) it_unsorted DISCARDING DUPLICATES ).
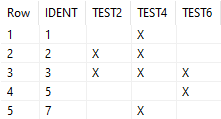
Was ist mit unserer Datenmenge passiert? Es wurde zuerst der Datensatz mit der Identifikation 3 aus der sortierten Tabelle übernommen und der Datensatz aus den unsortierten Daten wurde ignoriert. Vor allem bei nicht gleichen Datensätzen mit unterschiedlichen Informationen solltest du diese Regel beachten.
Fazit
Verschiedene Weg führen zu einer Lösung, doch du solltest dabei auch auf die Robustheit deines Codes gegen Fehler achten. Die erste einfache Lösung kann funktionieren, aber unter speziellen Bedingungen dann doch unerwartete Fehler verursachen.




