
ABAP Cloud - Parallelverarbeitung
Die Klasse CL_ABAP_PARALLEL gibt es bereits eine Weile und wird auch in ABAP Cloud verwendet. In diesem Artikel erfährst du mehr über die Nutzung und Wirkung.

Inhaltsverzeichnis
In diesem Artikel gehen wir etwas näher auf die beiden Varianten von CL_ABAP_PARALLEL ein und wie du sie nutzen kannst. Die Dokumentation an der Klasse ist bereits recht umfangreich, doch leider erklären sich nicht alle Details. Deshalb werden wir in diesem Artikel noch einmal genauer auf das Thema eingehen.
Einführung
In vielen Situationen kann es vorkommen, dass die Performance einer Aktion in einer Verarbeitung zu viel Zeit einnimmt, einfach weil zu viele Datensätze verarbeitet werden müssen. Dann hilft es meist, die Anzahl der Prozesse zu erhöhen, um so die Masse an Daten schneller abarbeiten zu können. Früher konnte man dazu die Verarbeitung in einen Funktionsbaustein auslagern, musste sich aber um das Handling der einzelnen Sessions selbst kümmern. Mittlerweile gibt es dafür die Klasse CL_ABAP_PARALLEL die zwei Szenarien zur Verfügung stellt.
Vorbereitung
In diesem Artikel verwenden wir einige Objekte, um den Großteil des Coding auszulagern und uns auf die wesentlichen Implementierungen zu beschränken. Wir verwenden dabei das Datenmodell aus unserer Core Data Service Schulung, um einiges an Logik zu implementieren. Allerdings möchten wir darauf hinweisen, dass der Quellcode und die Zugriffe nicht optimiert sind und nur verwendet werden, um etwas Laufzeit zu generieren.
CLASS zcl_bs_demo_para_data DEFINITION
PUBLIC FINAL
CREATE PUBLIC.
PUBLIC SECTION.
TYPES td_packed TYPE p LENGTH 15 DECIMALS 3.
TYPES ts_partner TYPE zbs_dmo_partner.
TYPES tt_partner TYPE STANDARD TABLE OF ts_partner WITH EMPTY KEY.
TYPES: BEGIN OF ts_result,
partner TYPE zbs_dmo_partner-partner,
name TYPE zbs_dmo_partner-name,
headers TYPE i,
positions TYPE i,
pos_per_head TYPE td_packed,
start_time TYPE utclong,
end_time TYPE utclong,
END OF ts_result.
TYPES tt_result TYPE STANDARD TABLE OF ts_result WITH EMPTY KEY.
METHODS get_partners
RETURNING VALUE(rt_result) TYPE tt_partner.
METHODS get_result_from_partner
IMPORTING is_partner TYPE ts_partner
RETURNING VALUE(rs_result) TYPE ts_result.
PRIVATE SECTION.
METHODS get_number_of_headers
IMPORTING is_partner TYPE ts_partner
RETURNING VALUE(rd_result) TYPE i.
METHODS get_number_of_positions
IMPORTING is_partner TYPE ts_partner
RETURNING VALUE(rd_result) TYPE i.
METHODS get_positions_per_head
IMPORTING is_partner TYPE ts_partner
RETURNING VALUE(rd_result) TYPE zcl_bs_demo_para_data=>td_packed.
ENDCLASS.
CLASS zcl_bs_demo_para_data IMPLEMENTATION.
METHOD get_partners.
SELECT FROM zbs_dmo_partner
FIELDS *
WHERE partner BETWEEN '1000000000' AND '1000000006'
INTO TABLE @rt_result.
ENDMETHOD.
METHOD get_result_from_partner.
DATA ls_result TYPE ts_result.
ls_result-start_time = utclong_current( ).
ls_result-partner = is_partner-partner.
ls_result-name = is_partner-name.
ls_result-headers = get_number_of_headers( is_partner ).
ls_result-positions = get_number_of_positions( is_partner ).
ls_result-pos_per_head = get_positions_per_head( is_partner ).
ls_result-end_time = utclong_current( ).
RETURN ls_result.
ENDMETHOD.
METHOD get_number_of_headers.
SELECT FROM zbs_dmo_invoice
FIELDS *
WHERE partner = @is_partner-partner
INTO TABLE @DATA(lt_head).
LOOP AT lt_head INTO DATA(ls_head).
rd_result += 1.
ENDLOOP.
ENDMETHOD.
METHOD get_number_of_positions.
SELECT FROM zbs_dmo_invoice
FIELDS *
WHERE partner = @is_partner-partner
INTO TABLE @DATA(lt_head).
LOOP AT lt_head INTO DATA(ls_head).
SELECT FROM zbs_dmo_position
FIELDS *
WHERE document = @ls_head-document
INTO TABLE @DATA(lt_position).
LOOP AT lt_position INTO DATA(ls_position).
rd_result += 1.
ENDLOOP.
ENDLOOP.
ENDMETHOD.
METHOD get_positions_per_head.
DATA lt_count TYPE STANDARD TABLE OF i WITH EMPTY KEY.
SELECT FROM zbs_dmo_invoice
FIELDS *
WHERE partner = @is_partner-partner
INTO TABLE @DATA(lt_head).
LOOP AT lt_head INTO DATA(ls_head).
SELECT FROM zbs_dmo_position
FIELDS *
WHERE document = @ls_head-document
INTO TABLE @DATA(lt_position).
DATA(ld_count) = 0.
LOOP AT lt_position INTO DATA(ls_position).
ld_count += 1.
ENDLOOP.
INSERT ld_count INTO TABLE lt_count.
ENDLOOP.
DATA(ld_sum) = 0.
LOOP AT lt_count INTO ld_count.
ld_sum += ld_count.
ENDLOOP.
rd_result = ld_sum / lines( lt_count ).
ENDMETHOD.
ENDCLASS.
Weiterhin gibt es eine Klasse zur Messung der Laufzeit. In diesem Fall greifen wir auf einen einfachen TIMESTAMPL zurück und berechnen die Differenz.
CLASS zcl_bs_demo_runtime DEFINITION
PUBLIC FINAL
CREATE PUBLIC.
PUBLIC SECTION.
METHODS constructor.
METHODS get_diff
RETURNING VALUE(rd_result) TYPE timestampl.
PRIVATE SECTION.
DATA md_started TYPE timestampl.
METHODS get_timestampl
RETURNING VALUE(rd_result) TYPE timestampl.
ENDCLASS.
CLASS zcl_bs_demo_runtime IMPLEMENTATION.
METHOD constructor.
md_started = get_timestampl( ).
ENDMETHOD.
METHOD get_diff.
rd_result = get_timestampl( ) - md_started.
ENDMETHOD.
METHOD get_timestampl.
GET TIME STAMP FIELD rd_result.
ENDMETHOD.
ENDCLASS.
Szenario 1 - Vererbung
In diesem Szenario erbt unsere Klasse vom Parallel-Objekt und wir implementieren die Logik in der DO Methode. Nachteil an diesem Szenario ist, dass wir uns selbst um das Packen und Auspacken der Payload kümmern müssen und damit mehr Schritte in unserer Verantwortung sind.
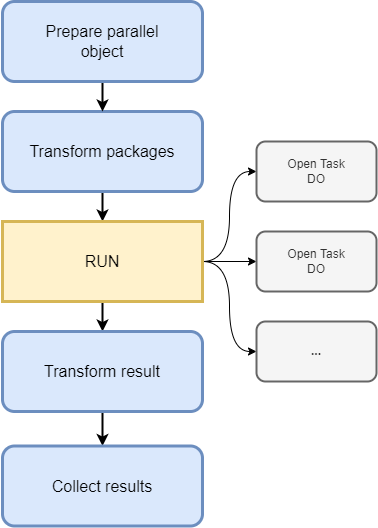
Aufbau
Die ausführende Klasse oder der Prozess sieht dabei wie folgt aus. Unsere Klasse erbt von CL_ABAP_PARALLEL und wir redefinieren die DO Methode.
CLASS zcl_bs_demo_para_inheriting DEFINITION
PUBLIC
INHERITING FROM cl_abap_parallel FINAL
CREATE PUBLIC.
PUBLIC SECTION.
METHODS
do REDEFINITION.
ENDCLASS.
CLASS zcl_bs_demo_para_inheriting IMPLEMENTATION.
METHOD do.
DATA ls_partner TYPE zcl_bs_demo_para_data=>ts_partner.
DATA lt_result TYPE zcl_bs_demo_para_data=>tt_result.
CALL TRANSFORMATION id SOURCE XML p_in
RESULT in = ls_partner.
WAIT UP TO 1 SECONDS.
INSERT NEW zcl_bs_demo_para_data( )->get_result_from_partner( ls_partner ) INTO TABLE lt_result.
CALL TRANSFORMATION id SOURCE out = lt_result
RESULT XML p_out.
ENDMETHOD.
ENDCLASS.
Während der Verarbeitung müssen wir nun den Binary Stream in unsere Daten konvertieren, um an das zu verarbeitende Paket zu kommen. Der Wait ist nur zu Testzwecken implementiert. Im Anschluss kann die eigentliche Verarbeitung des Pakets beginnen und das Ergebnis müssen wir dann wieder als Binary konvertieren und exportieren.
Ausführung
Wollen wir nun die Parallelisierung ausführen, benötigen wir im ersten Schritt einige Variablen und Objekte. Über die Tabelle LT_IN bauen wir die einzelnen Arbeitspakete auf, die dann parallel abgearbeitet werden sollen.
DATA ld_in TYPE xstring.
DATA lt_in TYPE cl_abap_parallel=>t_in_tab.
DATA lt_out TYPE zcl_bs_demo_para_data=>tt_result.
DATA lt_result TYPE zcl_bs_demo_para_data=>tt_result.
DATA(lo_timer) = NEW zcl_bs_demo_runtime( ).
DATA(lo_data) = NEW zcl_bs_demo_para_data( ).
DATA(lo_parallel) = NEW zcl_bs_demo_para_inheriting( p_num_tasks = 3 ).
Zu Testzwecken erzeugen wir uns ein Timer-Objekt zur Messung, unser Datenobjekt, das uns den Arbeitsvorrat zur Verfügung stellt und unser Parallelisierungsobjekt, welches die Aufgaben dann übernehmen soll. Im nächsten Schritt erzeugen wir die Arbeitspakete, indem wir die Struktur in ein XML Binary umwandeln und an die Tabelle LT_IN hängen.
LOOP AT lo_data->get_partners( ) INTO DATA(ls_partner).
CALL TRANSFORMATION id SOURCE in = ls_partner
RESULT XML ld_in.
INSERT ld_in INTO TABLE lt_in.
ENDLOOP.
Nun führen wir die RUN Methode aus und übergeben die einzelnen Datenpakete. Jede Zeile in der Tabelle erzeugt später einen eigenen Prozess bei der Verarbeitung.
lo_parallel->run( EXPORTING p_in_tab = lt_in
IMPORTING p_out_tab = DATA(lt_out_tab) ).
Ist der Methode fertig, dann wurden alle Pakete verarbeitet und wir erhalten das Ergebnis in der Tabelle LT_OUT_TAB. Zum Abschluss müssen wir nur noch das Binary entpacken und das Ergebnis zusammenführen.
LOOP AT lt_out_tab ASSIGNING FIELD-SYMBOL(<ld_out>).
CALL TRANSFORMATION id SOURCE XML <ld_out>-result
RESULT out = lt_out.
INSERT LINES OF lt_out INTO TABLE lt_result.
ENDLOOP.
Szenario 2 - Interface IF_ABAP_PARALLEL
Das erste Szenario war bereits sehr komplex, da wir uns jedes Mal um das Aus- und Einpacken der Daten selbst kümmern mussten. Viel einfacher geht es daher mit diesem Szenario. Wie du siehst, sind hier weniger Ausführungen notwendig.

Aufbau
Die Klasse für den Prozess sieht wie folgt aus, dabei erhalten wir dieses Mal über den Konstruktor unser Datenpaket und verwalten das Ergebnis innerhalb der Klasse. Dazu müssen wir das Interface IF_ABAP_PARALLEL implementieren und in der DO Methode die eigentliche Logik implementieren.
CLASS zcl_bs_demo_para_task DEFINITION
PUBLIC FINAL
CREATE PUBLIC.
PUBLIC SECTION.
INTERFACES if_abap_parallel.
METHODS constructor
IMPORTING is_partner TYPE zcl_bs_demo_para_data=>ts_partner.
METHODS get_result
RETURNING VALUE(rt_result) TYPE zcl_bs_demo_para_data=>tt_result.
PRIVATE SECTION.
DATA ms_partner TYPE zcl_bs_demo_para_data=>ts_partner.
DATA mt_result TYPE zcl_bs_demo_para_data=>tt_result.
ENDCLASS.
CLASS zcl_bs_demo_para_task IMPLEMENTATION.
METHOD constructor.
ms_partner = is_partner.
ENDMETHOD.
METHOD if_abap_parallel~do.
WAIT UP TO 1 SECONDS.
INSERT NEW zcl_bs_demo_para_data( )->get_result_from_partner( ms_partner ) INTO TABLE mt_result.
ENDMETHOD.
METHOD get_result.
RETURN mt_result.
ENDMETHOD.
ENDCLASS.
Hier verwenden wir die gleiche Logik wie im ersten Szenario, sparen uns allerdings die Transformation der Daten.
Ausführung
Auch in diesem Beispiel benötigen wir einige Variablen, allerdings nicht so viele wie im ersten Fall.
DATA lt_processes TYPE cl_abap_parallel=>t_in_inst_tab.
DATA lt_result TYPE zcl_bs_demo_para_data=>tt_result.
DATA(lo_timer) = NEW zcl_bs_demo_runtime( ).
DATA(lo_data) = NEW zcl_bs_demo_para_data( ).
Die Datenpakete sind in diesem Fall die einzelnen Instanzen, die wir an die Tabelle LT_PROCESSES hängen. In unserem Beispiel erzeugen wir pro Partner aus der Datenbank ein Datenpaket.
LOOP AT lo_data->get_partners( ) INTO DATA(ls_partner).
INSERT NEW zcl_bs_demo_para_task( ls_partner ) INTO TABLE lt_processes.
ENDLOOP.
Über die Methode RUN_INST starten wir die Parallelisierung und bekommen nach Abschluss in der Variable LT_FINISHED das Ergebnis.
NEW cl_abap_parallel( p_num_tasks = 3 )->run_inst( EXPORTING p_in_tab = lt_processes
IMPORTING p_out_tab = DATA(lt_finished) ).
Nun müssen wir nur noch die Ergebnisse aus den einzelnen Instanzen zusammensammeln und erhalten das Ergebnis der Prozessierung.
LOOP AT lt_finished INTO DATA(ls_finished).
INSERT LINES OF CAST zcl_bs_demo_para_task( ls_finished-inst )->get_result( ) INTO TABLE lt_result.
ENDLOOP.
Gesamtes Beispiel
Das vollständige Beispiel der ausführbaren Klasse für die beiden Szenarien findest du hier.
CLASS zcl_bs_demo_para_start DEFINITION
PUBLIC FINAL
CREATE PUBLIC.
PUBLIC SECTION.
INTERFACES if_oo_adt_classrun.
PRIVATE SECTION.
METHODS start_scenario_1
IMPORTING io_out TYPE REF TO if_oo_adt_classrun_out.
METHODS start_scenario_2
IMPORTING io_out TYPE REF TO if_oo_adt_classrun_out.
ENDCLASS.
CLASS zcl_bs_demo_para_start IMPLEMENTATION.
METHOD if_oo_adt_classrun~main.
out->write( 'Scenario 1 - Inheritance' ).
start_scenario_1( out ).
out->write( '-' ).
out->write( 'Scenario 2 - Interface' ).
start_scenario_2( out ).
ENDMETHOD.
METHOD start_scenario_1.
DATA ld_in TYPE xstring.
DATA lt_in TYPE cl_abap_parallel=>t_in_tab.
DATA lt_out TYPE zcl_bs_demo_para_data=>tt_result.
DATA lt_result TYPE zcl_bs_demo_para_data=>tt_result.
DATA(lo_timer) = NEW zcl_bs_demo_runtime( ).
DATA(lo_data) = NEW zcl_bs_demo_para_data( ).
DATA(lo_parallel) = NEW zcl_bs_demo_para_inheriting( p_num_tasks = 3 ).
LOOP AT lo_data->get_partners( ) INTO DATA(ls_partner).
CALL TRANSFORMATION id SOURCE in = ls_partner
RESULT XML ld_in.
INSERT ld_in INTO TABLE lt_in.
ENDLOOP.
lo_parallel->run( EXPORTING p_in_tab = lt_in
IMPORTING p_out_tab = DATA(l_out_tab) ).
LOOP AT l_out_tab ASSIGNING FIELD-SYMBOL(<l_out>).
CALL TRANSFORMATION id SOURCE XML <l_out>-result
RESULT out = lt_out.
INSERT LINES OF lt_out INTO TABLE lt_result.
ENDLOOP.
io_out->write( lo_timer->get_diff( ) ).
io_out->write( lt_result ).
ENDMETHOD.
METHOD start_scenario_2.
DATA lt_processes TYPE cl_abap_parallel=>t_in_inst_tab.
DATA lt_result TYPE zcl_bs_demo_para_data=>tt_result.
DATA(lo_timer) = NEW zcl_bs_demo_runtime( ).
DATA(lo_data) = NEW zcl_bs_demo_para_data( ).
LOOP AT lo_data->get_partners( ) INTO DATA(ls_partner).
INSERT NEW zcl_bs_demo_para_task( ls_partner ) INTO TABLE lt_processes.
ENDLOOP.
NEW cl_abap_parallel( p_num_tasks = 3 )->run_inst( EXPORTING p_in_tab = lt_processes
IMPORTING p_out_tab = DATA(lt_finished) ).
LOOP AT lt_finished INTO DATA(ls_finished).
INSERT LINES OF CAST zcl_bs_demo_para_task( ls_finished-inst )->get_result( ) INTO TABLE lt_result.
ENDLOOP.
io_out->write( lo_timer->get_diff( ) ).
io_out->write( lt_result ).
ENDMETHOD.
ENDCLASS.
Wenn du das Beispiel ausführst, erhältst du die folgende Ausgabe.
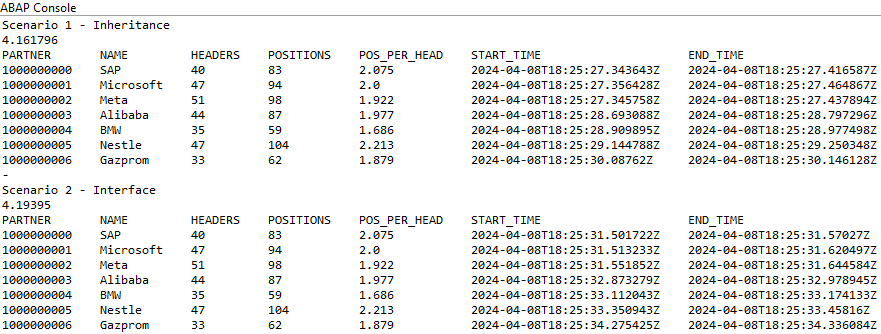
Einstellungen
Wie sieht es nun eigentlich mit den Einstellungen für die Klassen aus? Der Konstruktor der Klasse CL_ABAP_PARALLEL bietet einige Einstellungsmöglichkeiten, um die Parallelisierung und die Auslastung des Systems zu steuern. Über die ABAP Docs, in Eclipse über F2 öffnen, erhalten wir eine recht gute Erklärung der Einstellungen, aber leider nicht, wie die Parameter zusammen wirken.

Wird P_PERCENTAGE versorgt, wird dieser Wert zur Berechnung der zu verwendenden Prozesse verwendet. Hier sind Werte von 0 bis 100 möglich, also wie viel Prozent der nutzbaren Prozesse für die Parallelisierung verwendet werden. P_NUM_TASKS gibt eine fixe Anzahl Prozesse an, die für die Parallelisierung verwendet werden dürfen. Werden beide Werte angegeben, wird der Prozentwert verwendet.
Hier einmal ein Beispiel für den Parameter P_NUM_TASKS, indem wir der Verarbeitung 1, 3 und 9 Prozesse zur Verfügung stellen. Umso mehr Prozesse wir stellen, desto schneller wird die Durchlaufzeit zur Ermittlung der Ergebnisse. Wie du an den Startzeiten siehst, werden die verschiedenen Pakete zu unterschiedlichen Zeiten gestartet oder im letzten Fall sogar alle gleichzeitig.
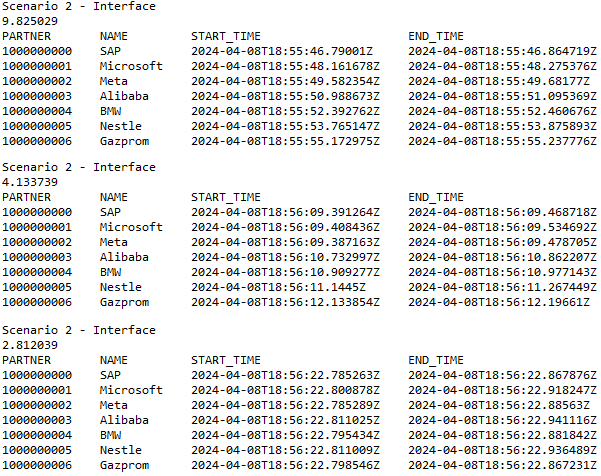
Über die Methode RUN und RUN_INST kannst du noch ein Debug-Flag (P_DEBUG) setzen, wenn du dies machst, dann werden alle Prozesse nacheinander durchlaufen und es erfolgt keine Ausführung als RFC. Damit kannst du den Prozess debuggen und nach Fehlern suchen.
Fazit
Wir empfehlen dir die Nutzung von Szenario 2, da es einfacher und mit weniger Code implementierbar ist. Grundsätzlich sollte dir der Artikel dabei helfen, im nächsten Projekt einfach eine Parallelisierung von Prozessen und damit einen Performancegewinn zu realisieren. Die gezeigte Klasse ist auch in einem älteren Release bis 7.50 möglich, kann sich dann aber in einzelnen Inhalten unterscheiden.
Weitere Informationen:
SAP Blog - CL_ABAP_PARALLEL
Blog von Sascha Wächter


