
ABAP - CDS Extraktor
Wie funktioniert der CDS Extraktor in ABAP und welche Herausforderungen gibt es bei der Entwicklung damit. In diesem Artikel schauen wir uns ein paar Details an.

Inhaltsverzeichnis
In diesem Artikel schauen wir uns einmal die Extraktion von CDS Views und Hierarchien an, die wir auch für die Aufbereitung der CDS Informationen nehmen. Dabei wirst du etwas über den Extraktor aber auch die Besonderheiten der Standardklassen erfahren.
Einleitung
Vor einer Weile hatten wir das CDS Feld Mapping in der Beta Phase veröffentlicht. Hierbei handelt es sich um eine Auflistung von Core Data Services und Tabellen und deren Verbindung über die Felder. Wenn du auf ABAP Cloud wechselst, stehst du vor der Herausforderung, dass du anstatt den bekannten Tabellen, die neuen Core Data Services verwenden sollst. Das Mapping von alter Tabelle auf den neuen CDS Views findest du einfach im Cloudification Repository oder am eigentlichen Objekt in deinem System.
Doch welches Feld ist nun eigentlich auf welches Feld im Core Data Service gemappt und sind es wirklich die gesuchten Daten? Das ist meist nicht auf einen Blick ableitbar, da das Mapping über mehrere Core Data Services läuft. Jedes Feld in mühevoller Kleinarbeit nachvollziehen zu können, macht daher wenig Sinn.
Ausführung
Für die Ausführung des Extraktors stehen dir 4 öffentliche Methoden zur Verfügung. Diese Methoden sind hier noch einmal kurz erklärt:
- GET_MAPPING_IN_JSON_FORMAT - Lesen des Repository, Ermittlung des Mappings als Tabelle und Konvertierung der Daten in das JSON Format.
- GET_MAPPING_AS_TABLE - Lesen des Repository und Ermittlung des Mappings als Tabelle
- GET_MAPPING_FROM_CDS - Ermittlung des Mappings anhand einer Tabelle und eines Core Data Services.
- GET_RELEVANT_OBJS_FROM_REPO - Lesen des Repository und Zusammenstellung der offenen Objekte für die Ermittlung des Mappings.
Die MAIN Methode verwendet immer die Methode GET_MAPPING_IN_JSON_FORMAT um die Daten zu ermitteln. Dabei werden nicht alle Daten auf einem gelesen. Zuvor werden bekannte Mappings aus dem GitHub Repository geladen und nur noch nicht gemappte Kombinationen verarbeitet. Über die beiden Ranges LT_R_CDS und LT_R_TABLE kannst du die Menge noch einmal einschränken, wenn du nur verschiedene Objekte testen willst.
Möchtest du eine Kombination ausführen, die bereits gemappt wurde oder gar nicht vorhanden ist, kannst du das über die Struktur LS_FIXED steuern. Dazu ein Beispiel:
ls_fixed = VALUE #( cds = 'I_CADOCUMENTBPITEMPHYSICAL'
table = 'DFKKOP' ).
Abgleich Repository
Die Logik sieht vor, dass wir im ersten Schritt das Cloudification Repository einlesen und alle Kombinationen Tabelle zu Core Data Service lesen. Im Anschluss lesen wir das Repository des Mapping Tools die bereits gemappten Daten und ergänzen diese um nicht freigegebene Views. So erhalten wir eine Menge an Objekten, die noch gemappt werden sollen. Sind alle Objekte bereits gemappt, wird die Logik keine Ermittlung mehr durchführen. Die entsprechenden Links zu den Objekten findest du als Konstanten in der Klasse.
CONSTANTS c_url_cloudification_repo TYPE string VALUE `https://raw.githubusercontent.com/SAP/abap-atc-cr-cv-s4hc/main/src/objectReleaseInfoLatest.json`.
CONSTANTS c_url_mappings TYPE string VALUE `https://raw.githubusercontent.com/Xexer/abap-cds-field-mapping/main/mapping/core-data-services.json`.
CONSTANTS c_url_not_released TYPE string VALUE `https://raw.githubusercontent.com/Xexer/abap-cds-field-mapping/main/mapping/not-released-views.json`.
Extraktion
In diesem Abschnitt gehen wir etwas tiefer in Extraktion der Daten ein. Wir starten daher mit der eigentlichen Methode die rekursiv aufgerufen wird, um durch die verschiedenen Ebenen an Core Data Services zu gehen. Am Ende liefert uns die Logik eine Tabelle in dieser Form.
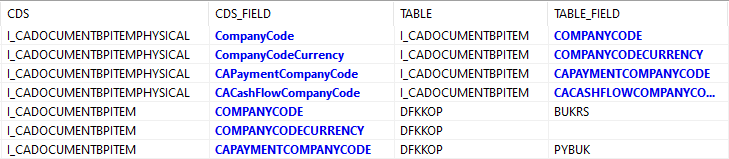
Über die Tabelle können wir dann prüfen, ob wir vom Core Data Service bis zum Datenbankfeld kommen können, indem wir die verschiedenen Ebenen nach unten lesen. Haben wir dann einen Eintrag mit der zu suchenden Tabelle gefunden, geben wir den Feldnamen zurück (Methode FIND_TABLE_FIELD). In diesem Beispiel wäre das:
- I_CADOCUMENTBPITEMPHYSICAL | CompanyCode -> I_CADOCUMENTBPITEM | COMPANYCODE
- I_CADOCUMENTBPITEM | COMPANYCODE -> DFKKOP | BUKRS
CDS Informationen
Beginnen wir nun mit der rekursiven Ermittlung der Daten. Dazu verwenden wir die Standardklasse XCO_CDS um an die Informationen zu unserem Objekt zu gelangen. In der Methode GET_FIELDS_N_CONTENT_FROM_CDS wollen wir die Felder und den Kontext lesen.
DATA(lo_cds) = xco_cds=>view( id_cds ).
IF lo_cds->exists( ).
es_content = lo_cds->content( )->get( ).
et_fields = lo_cds->fields->all->get( ).
ENDIF.
Dazu erzeugen wir ein CDS Objekt, prüfen, ob es existiert und lassen uns die Felder in Form von Objekten geben, sowie den Kontext mit weiteren Informationen zum Objekt. Der Kontext erhält Informationen zur Datenquelle, also unser nächstes Objekt, und zu möglichen anderen Objekten.

Schauen wir uns dann den Core Data Service an, finden wir die gleichen Informationen zur Datenquelle und das ein Alias verwendet wurde für die Daten.

Wir hatten damals mit der Klasse XCO_CP_CDS angefangen zu entwickeln, da diese für ABAP Cloud auch freigegeben ist. Die Klasse filtert allerdings Objekte ohne C1-Freigabe heraus, wodurch wir nie bis zur Tabelle kommen können, da die anderen Views nicht freigegeben sind.
Aufbereitung
Leider sind die Felder nicht immer einfache Mappings, sondern in manchen Fällen werden CDS Funktionen verwendet, zum Beispiel um einen Cast durchzuführen oder einen absoluten Wert zu ermitteln.
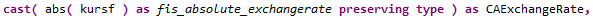
Aktuell gelangen wir nur über die Expression an den Inhalt des Felder vor dem Alias. Wenn wir uns die Struktur anschauen, wären hier die entsprechenden Informationen, um die Felder aufzulösen, allerdings kommen wir nicht an die Attribute, da diese auf Privat stehen.
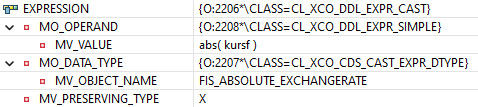
Wir können uns allerdings das komplette Statement zurückgeben lassen, fügen dieses dann zusammen, um es im Anschluss selbst auseinander nehmen zu können.
DATA(lo_strings) = io_expression->if_xco_text~get_lines( ).
DATA(ld_result) = concat_lines_of( table = lo_strings->value
sep = ` ` ).
Über die Methode REPLACE_CDS_FUNCTIONS versuchen wir dann die Funktionen aufzulösen und an das eigentliche Feld zu gelangen. Dazu zerlegen wir die Funktionen nacheinander und erhalten eine Tabelle von außen nach innen.

Daher beginnen wir mit dem letzten Element und übernehmen die Daten als Feldname. An dieser Stelle handelt es sich um eine einfache Logik und wir unterstützen aktuell keine komplexen Statements mit mehreren Komponentengruppen, wie CASE.
ALIAS
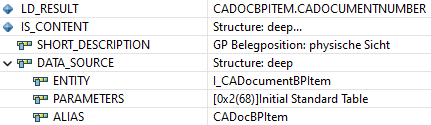
Zum Abschluss müssen wir in einigen Views den Alias ersetzen, dieser kann aus dem Namen des Views bestehen oder selbst einen Alias verwenden. In LD_RESULT befindet sich das aktuell ermittelte Feld, welches noch einen ALIAS im Namen hat. Im Kontext des Core Data Service findest du unter DATA_SOURCE die Informationen zu ENTITY (der aktuelle CDS View) und dem ALIAS (Alias der Entität). Mit eine der beiden Informationen können wir den ALIAS am Feld dann auch auflösen.
Quellcode
Damit wäre der Extraktor auch so weit erklärt und vollständig. Wenn du Interesse am Quellcode insgesamt hast, findest du diesen bei uns im GitHub Repository. Solltest du Fehler finden, freuen wir uns über einen Issue im Repository. Ansonsten kannst du auch mit weiteren Views/Tabellen beitragen, die vielleicht nicht unbedingt von SAP freigegeben wurden.
Automatisierung
Wie geht es nun mit dem Mapping weiter? Grundsätzlich kannst du nun das Mapping nutzen, um die neuen Entitäten und Felder in deinem Fachmodul zu lernen und zu nutzen. Wir arbeiten an einem weiteren Tool zur Nutzung des Repository, um SELECT Statements zu konvertieren. Das Tool befindet sich aktuell in der ALPHA Phase und kann nur sehr einfache Statements umwandeln.

Fazit
Um an alle Informationen eines CDS Views und dem Mapping zu kommen, bedarf es etwas mehr Aufwand. Der Vorteil aus der Liste ist die Zeitersparnis, die du damit gewinnen kannst, wenn du die Informationen nutzt. Wenn du mehr Interesse an der Funktionsweise hast, kannst du dir den Quellcode im Repository anschauen.




