
ABAP Tools - Arbeiten mit Eclipse (Performance Analyse)
In diesem Artikel befassen wir uns mit der Performance Analyse von Objekten über die ABAP Development Tools und die Möglichkeiten von Traces.

Inhaltsverzeichnis
Bisher hat mal als Entwickler vor allem die klassischen Transaktionen wie ST01, SAT oder ST12 verwendet, um die Leistung von Quellcode und Verbindungen zu prüfen und gegebenenfalls zu optimieren. In diesem Artikel wollen wir einmal auf die Möglichkeiten der ABAP Development Tools eingehen und wie du sie effizient für dich verwenden kannst.
Einleitung
Die sogenannten Traces braucht man immer dann, wenn man die Vermutung hat, dass Quellcode nicht unbedingt sehr schnell läuft oder die Nacht nicht mehr für die Verarbeitung der Daten reicht. Aber als Entwickler sollte man regelmäßig seinen eigenen Quellcode prüfen, ob man auch nach den entsprechenden Best-Practices gearbeitet hat. Auch bei der Migration von R/3 auf S/4 HANA sollten einige Dinge beachtet werden und neben dem ABAP Test Cockpit, kurz ATC, können solche Traces ungemein helfen.
Vorbereitung
Damit du nicht auf der grünen Wiese starten musst, haben wir drei Objekte für dich vorbereitet, an denen du arbeiten kannst. Dazu legen wir eine eigene Tabelle im System an:
@EndUserText.label : 'Tabelle für Performance'
@AbapCatalog.tableCategory : #TRANSPARENT
define table zedu_performance {
key client : abap.clnt not null;
key identifier : sysuuid_x16 not null;
description : abap.char(150);
@Semantics.amount.currencyCode : 'zedu_performance.currency'
amount : abap.curr(15,2);
currency : abap.cuky;
blob : abap.string(0);
ndate : abap.dats;
}
Die Daten enthalten später zufällige Daten, verschiedene Datentypen und Informationen. HANA ist optimiert auf die Ablage von gleichen und ähnlichen Spalteninhalten, deshalb erzeugen wird für die Felder DESCRIPTION und BLOB komplett zufallsbasierte Informationen. Die Klasse zur Initialisierung der Daten sieht wie folgt aus:
CLASS zcl_edu_performance_init DEFINITION PUBLIC FINAL CREATE PUBLIC.
PUBLIC SECTION.
INTERFACES if_oo_adt_classrun.
PRIVATE SECTION.
DATA mo_rand_amount TYPE REF TO zcl_bs_demo_random.
DATA mo_rand_currency TYPE REF TO zcl_bs_demo_random.
DATA mo_rand_text TYPE REF TO zcl_bs_demo_random.
DATA mo_rand_blob TYPE REF TO zcl_bs_demo_random.
DATA mo_rand_date TYPE REF TO zcl_bs_demo_random.
DATA md_letters TYPE string.
METHODS get_random_currency
RETURNING VALUE(rd_result) TYPE waers.
METHODS get_description
RETURNING VALUE(rd_result) TYPE zedu_performance-description.
METHODS get_blob
RETURNING VALUE(rd_result) TYPE zedu_performance-blob.
METHODS get_letter
RETURNING VALUE(rd_result) TYPE string.
METHODS get_date
RETURNING VALUE(rd_result) TYPE d.
ENDCLASS.
CLASS zcl_edu_performance_init IMPLEMENTATION.
METHOD if_oo_adt_classrun~main.
DATA lt_database TYPE STANDARD TABLE OF zedu_performance WITH EMPTY KEY.
md_letters = to_lower( sy-abcde ) && to_upper( sy-abcde ).
mo_rand_amount = NEW zcl_bs_demo_random( id_min = 10 id_max = 150 ).
mo_rand_currency = NEW zcl_bs_demo_random( id_min = 1 id_max = 4 ).
mo_rand_text = NEW zcl_bs_demo_random( id_min = 1 id_max = 52 ).
mo_rand_blob = NEW zcl_bs_demo_random( id_min = 5000 id_max = 50000 ).
mo_rand_date = NEW zcl_bs_demo_random( id_min = 0 id_max = 730 ).
DELETE FROM zedu_performance.
COMMIT WORK.
" Create 50000 datasets
DO 100 TIMES.
DO 500 TIMES.
INSERT VALUE #( identifier = cl_system_uuid=>create_uuid_x16_static( )
description = get_description( )
amount = mo_rand_amount->get_random_number( )
currency = get_random_currency( )
blob = get_blob( )
ndate = get_date( ) )
INTO TABLE lt_database.
ENDDO.
INSERT zedu_performance FROM TABLE @lt_database.
COMMIT WORK.
CLEAR lt_database.
ENDDO.
out->write( |Datasets for ZEDU_PERFORMANCE created!| ).
ENDMETHOD.
METHOD get_random_currency.
CASE mo_rand_currency->get_random_number( ).
WHEN 1.
rd_result = 'EUR'.
WHEN 2.
rd_result = 'USD'.
WHEN 3.
rd_result = 'RUB'.
WHEN 4.
rd_result = 'CHF'.
ENDCASE.
ENDMETHOD.
METHOD get_description.
DO 150 TIMES.
rd_result &&= get_letter( ).
ENDDO.
ENDMETHOD.
METHOD get_blob.
DO mo_rand_blob->get_random_number( ) TIMES.
rd_result &&= get_letter( ).
ENDDO.
ENDMETHOD.
METHOD get_letter.
rd_result = substring( val = md_letters off = CONV i( mo_rand_text->get_random_number( ) - 1 ) len = 1 ).
ENDMETHOD.
METHOD get_date.
rd_result = sy-datum - mo_rand_date->get_random_number( ).
ENDMETHOD.
ENDCLASS.
Hinweis: Die Ausführung der Klasse wird etwas Zeit in Anspruch nehmen, da die Generierung der zufälligen Daten und BLOBs viel Performance benötigt. Für die Erzeugung der Zufallszahlen verwenden wir einen eigenen Zufallsgenerator der die Standardklasse von SAP nutzt.
Nun benötigen wir noch die Klasse, die wir optimieren wollen. Dazu haben wir einmal eine Beispielklasse entwickelt, die die Daten aus der Tabelle liest, die relevanten Währungen ermittelt und die Summe für einen Zeitraum berechnet:
CLASS zcl_edu_performance_issue DEFINITION PUBLIC FINAL CREATE PUBLIC.
PUBLIC SECTION.
INTERFACES if_oo_adt_classrun.
PRIVATE SECTION.
TYPES ts_data TYPE zedu_performance.
TYPES tt_data TYPE STANDARD TABLE OF zedu_performance WITH DEFAULT KEY.
DATA mt_data TYPE tt_data.
METHODS run_class_logic
IMPORTING io_out TYPE REF TO if_oo_adt_classrun_out.
METHODS select_data.
METHODS get_relevant_currencies
RETURNING VALUE(rt_result) TYPE tt_data.
METHODS get_sum_for_currency_and_time
IMPORTING id_currency TYPE ts_data-currency
id_from TYPE ts_data-ndate
id_to TYPE ts_data-ndate
RETURNING VALUE(rd_result) TYPE ts_data-amount.
ENDCLASS.
CLASS zcl_edu_performance_issue IMPLEMENTATION.
METHOD if_oo_adt_classrun~main.
GET RUN TIME FIELD DATA(ld_start).
run_class_logic( out ).
GET RUN TIME FIELD DATA(ld_end).
out->write( |Runtime of code: { ld_end - ld_start }| ).
ENDMETHOD.
METHOD run_class_logic.
select_data( ).
DATA(lt_currencies) = get_relevant_currencies( ).
LOOP AT lt_currencies INTO DATA(ls_currency).
DATA(ld_amount) = get_sum_for_currency_and_time( id_currency = ls_currency-currency
id_from = '20220101'
id_to = '20220630' ).
io_out->write( |Sum for currency { ls_currency-currency } is { ld_amount }.| ).
ENDLOOP.
ENDMETHOD.
METHOD select_data.
SELECT FROM zedu_performance
FIELDS *
INTO TABLE @mt_data.
ENDMETHOD.
METHOD get_relevant_currencies.
rt_result = mt_data.
SORT rt_result BY currency.
DELETE ADJACENT DUPLICATES FROM rt_result COMPARING currency.
ENDMETHOD.
METHOD get_sum_for_currency_and_time.
LOOP AT mt_data INTO DATA(ls_data)
WHERE currency = id_currency
AND ndate >= id_from
AND ndate <= id_to.
rd_result += ls_data-amount.
ENDLOOP.
ENDMETHOD.
ENDCLASS.
Führen wir nun die Klasse aus, erhalten wir das Ergebnis einmal für den Kaltstart (kein Datenbankpuffer vorhanden) und im zweiten Lauf mit Datenbankpuffer. Immerhin dauert die Ausführung der Klasse 19 Sekunden, was auf einem S/4 HANA System zu lange ist.
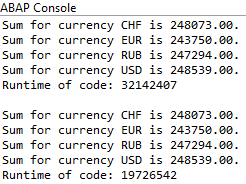
ABAP Profiling
Für die Durchführung eines Trace empfiehlt sich eine eigene Perspektive, die "ABAP Profiling" Perspektive die du über "Window -> Perspective -> Open Perspective -> Others ..." auswählen und öffnen kannst. Im einfachsten Fall verwendest du den Button oben Rechts neben den anderen Perspektiven. Wie so eine Perspektive aussehen kann, findest du hier im Bild.

Im oberen Bereich findest du das Objekt und später die Auswertung, Rechts die Eigenschaften und unten die beiden Views "ABAP Trace Requests" und "ABAP Traces", die wir für die weitere Arbeit benötigen.
ABAP Trace Requests
Der View zeigt alle geöffneten Systeme an, auf die du Zugriff hast. Unter den Systemen findest du die verschiedenen Traces die in der Vergangenheit durchgeführt wurden, entsprechend auf den aktuellen User eingestellt. Diese Einstellung kannst du jederzeit anpassen, um die Traces deiner Kollegen zu finden.

In diesem View erzeugst du auf dem System deine Trace Anfragen, schaltest somit den Trace ein. Dazu einfach das auf das gewünschte System ein Rechts-Klick machen und über das Kontext-Menü den Eintrag "Create Trace Request ..." wählen.

Im nächsten Bild kannst du deinen Trace konfigurieren, hier stehen verschiedene Methoden zur Verfügung, je nachdem was du genauer untersuchen möchtest. Um es einfach zu halten, setzen wir auf "Any" und schränken auf unsere Klasse und unseren User ein. Die Anzahl, hier auf drei, bedeutet wie viele Traces das System durchführt, bevor der Trace Request deaktiviert wird.
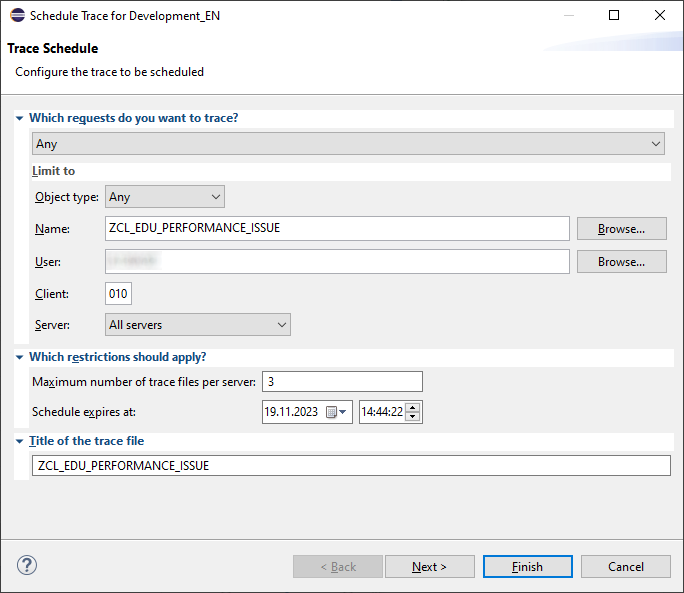
Neben Any, stehen auch: Web Requests (HTTP), Reports and Transactions (Dialog), Remote function call (RFC), Background Jobs (Batch) und Shared Objects Area zur Verfügung. Mit "Next" kommen wir auf das nächste Bild, um dort weitere Einstellungen und Einschränkungen vorzunehmen, um zum Beispiel die Größe des Logs klein zu halten.

Mit "Finish" ist der Trace bereit und wir führen die Console Application einmal aus, um unseren ersten Trace durchführen.
ABAP Traces
Nach dem Ausführen einmal das System im View "ABAP Traces" aktualisieren und unser erster Trace sollte auftauchen. Mit einem Doppel-Klick darauf, wird die Übersicht des Traces neben dem Quellcode angezeigt.
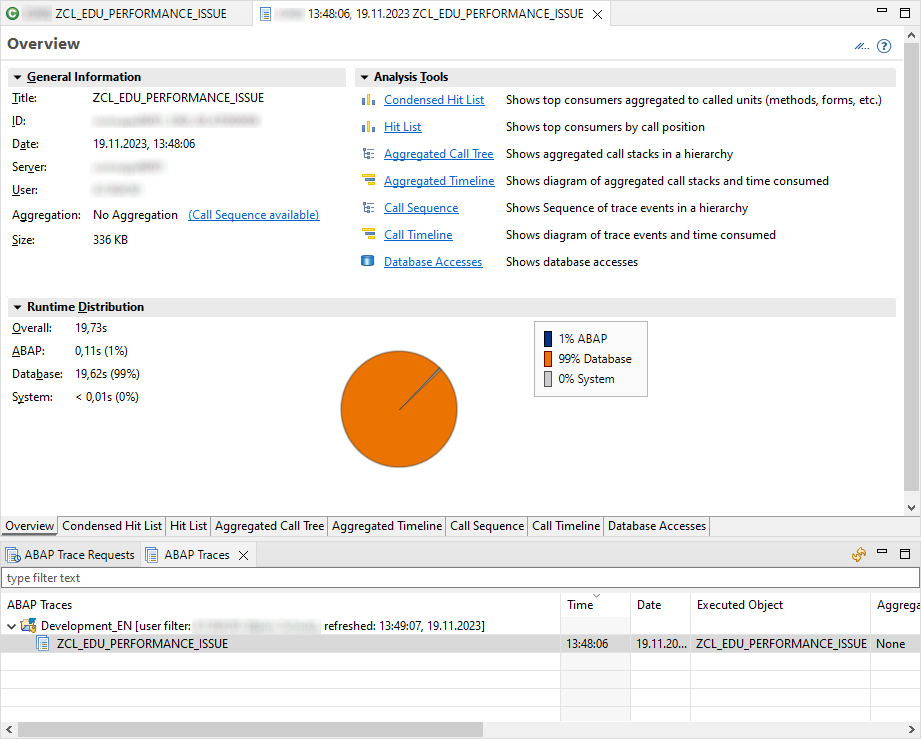
Neben der generellen Übersicht finden wir unten in den Reitern oder oben unter dem Punkt "Analysis Tools" weitere Einblicke in den Trace. Für unser Beispiel schauen wir uns einmal zwei verschiedene Views an.
Call Sequence
Hier werden die Aufrufe der Routinen hierarchisch dargestellt, dahinter finden sich die entsprechenden Laufzeiten wieder. Hier kannst du den Aufruf des Codings folgen und Stellen identifizieren, wo viel Zeit verloren geht.

Call Timeline
Der View digitalisiert das Ergebnis als Zeitstrahl und zeigt noch einmal deutlich an welchen Stellen viel Zeit verbraucht wird. Im unteren Teil erhältst du eine Übersicht über die verschiedenen Farben, wenn du mit der Maus über den Balken gehst, werden auch Informationen zum Statement eingeblendet.

Hit List
Eigentlich bereits der erste View in den man schauen sollte. Wenn du nach der Spalte "Own Time" sortierst, bekommst du einen Blick in die Langläufer und Performancefresser und kannst direkt die passenden Methoden und Statements optimieren.

Properties
Vielleicht hast du dich schon gefragt, wieso wir auch den "Properties" View für die Ansicht empfehlen? Immer wenn du einen Eintrag wählst, werden verschiedene Informationen angezeigt. So zum Beispiel bei einem Klick in der "Hit List":
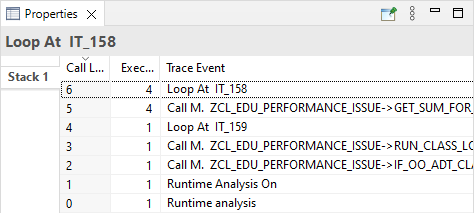
Lösung
Im folgenden Abschnitt erhältst du die Optimierung des Quellcodes, zuerst als Code im Folgenden dann in textueller Form. Wenn du erst einmal in Ruhe den Trace durchführen willst, dann einfach diesen Abschnitt pausieren und deine Analysen und Optimierungen durchführen.
CLASS zcl_edu_performance_fixed DEFINITION PUBLIC FINAL CREATE PUBLIC.
PUBLIC SECTION.
INTERFACES if_oo_adt_classrun.
PRIVATE SECTION.
TYPES ts_data TYPE zedu_performance.
TYPES tt_data TYPE STANDARD TABLE OF zedu_performance WITH DEFAULT KEY.
DATA mt_data TYPE tt_data.
METHODS run_class_logic
IMPORTING io_out TYPE REF TO if_oo_adt_classrun_out.
METHODS get_relevant_currencies
RETURNING VALUE(rt_result) TYPE tt_data.
METHODS get_sum_for_currency_and_time
IMPORTING id_currency TYPE ts_data-currency
id_from TYPE ts_data-ndate
id_to TYPE ts_data-ndate
RETURNING VALUE(rd_result) TYPE ts_data-amount.
ENDCLASS.
CLASS zcl_edu_performance_fixed IMPLEMENTATION.
METHOD if_oo_adt_classrun~main.
GET RUN TIME FIELD DATA(ld_start).
run_class_logic( out ).
GET RUN TIME FIELD DATA(ld_end).
out->write( |Runtime of code: { ld_end - ld_start }| ).
ENDMETHOD.
METHOD run_class_logic.
DATA(lt_currencies) = get_relevant_currencies( ).
LOOP AT lt_currencies INTO DATA(ls_currency).
DATA(ld_amount) = get_sum_for_currency_and_time( id_currency = ls_currency-currency
id_from = '20220101'
id_to = '20220630' ).
io_out->write( |Sum for currency { ls_currency-currency } is { ld_amount }.| ).
ENDLOOP.
ENDMETHOD.
METHOD get_relevant_currencies.
SELECT FROM zedu_performance
FIELDS DISTINCT currency
INTO CORRESPONDING FIELDS OF TABLE @rt_result.
ENDMETHOD.
METHOD get_sum_for_currency_and_time.
SELECT FROM zedu_performance
FIELDS SUM( amount ) AS amount
WHERE currency = @id_currency
AND ndate >= @id_from
AND ndate <= @id_to
INTO @rd_result.
ENDMETHOD.
ENDCLASS.
Welche Änderungen haben wir nun eigentlich vorgenommen? Hier noch einmal die komplette Auflösung:
- Einschränkung Felder beim SELECT - Ein SELECT * kann auf einem S/4 HANA System zu Performanceproblemen führen, vor allem wenn man nicht alle Felder benötigt oder sogar BLOB Objekte auf Zeilenebene enthalten sind.
- Split des SELECT - Auf einem R/3 System war es durchaus sinnvoll, erst einmal alle Daten einzulesen und dann die Verarbeitung im Quellcode durchzuführen. Hier sparen wir uns aber die Logik und lassen die Datenbank für uns arbeiten (Lesen der vorhandenen Währungen, Ermittlung der Summe pro Zeitraum)
Bereits nach der Auflösung des SELECT * verbessert sich die Laufzeit auf ca. 200 Millisekunden ohne Puffer.
SELECT FROM zedu_performance
FIELDS identifier, amount, currency, ndate
INTO CORRESPONDING FIELDS OF TABLE @mt_data.
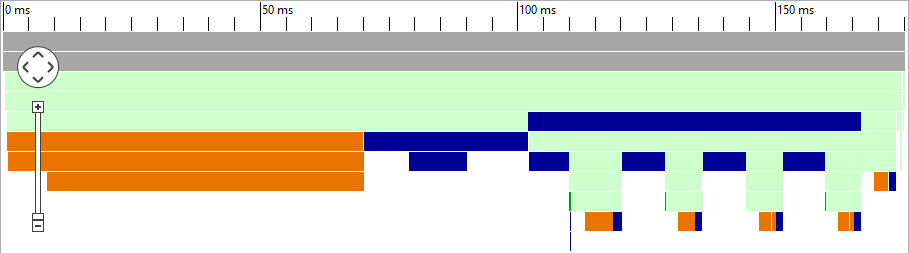
Dazu noch die neue "Call Timeline" aus einam zweiten Trace, der Datenbankzugriff benötigt nur noch knapp die Hälfte der Zeit. Weiterhin ist die Verarbeitung im Loop sehr gut zu sehen. Im Ergebnis oben haben wir noch einmal das Lesen über mehrere Zugriffe optimiert:
Fazit
Die Trace Tools sind übersichtlich und einfach zu bedienen und bieten umfangreiche Möglichkeiten zur Auswertung. Es lohnt sich immer ein Blick auf die verschiedenen Auswertungsmethoden zu werfen und verschiedene Traces miteinander zu vergleichen.

