RAP - Hybrid Pattern
Werfen wir einen Blick auf das Hybrid Pattern in der Entwicklung von RAP Objekten. Für wen ist das Szenario gedacht, wie funktioniert es und welche Grundbestandteile sind nötig.

Inhaltsverzeichnis
In diesem Artikel schauen wir uns den Aufbau und die Verwendung des Hybrid Pattern an. Dabei werden wir eine Anwendung bauen und uns die Unterschiede anschauen.
Einleitung
Das ABAP RESTful Application Programming Model ist das neue Modell in ABAP, um Cloud Ready und Clean Core Anwendungen zu erstellen. Mit RAP lassen sich neben Anwendungen, auch Schnittstellen für den internen und externen Gebrauch zur Verfügung stellen. Mit den neusten Features ist RAP sehr flexibel was den Aufbau und die Nutzung angeht, weshalb wir die Anwendungen in verschiedene Pattern aufteilen möchten.
Aufbau
Beim "Hybrid Pattern" geht es vor allem um. Die hybride Entwicklung von Anwendungsszenarien über mehrere Systeme hinweg. Dabei haben wir eine oder mehrere Remote Sources, die wir zusammen mit einer lokalen Source im System verbinden und danach Zusammen modellieren dies kann Über 2 Wege aktuell passieren eine Customente, die Oder eine External Entity? In diesem Artikel schauen wir uns im Detail einmal die External Entity an. Und gehen das zuerst einmal die Abgrenzung? Dabei verwenden wir die folgende Legende für das Modell.
Dazu die folgenden Merkmale zur Abgrenzung:
- Datenquelle von mindestens einem Remote System (oft im Side-by-Side Szenario)
- Anwendung basiert auf lokalen und Remote Daten
- Aktuell werden hier zwei Technologien verwendet (Custom Entity mit Consumption Model oder External Entity)

In unserem Szenario haben wir unsere Hauptdaten, die wir über eine External Entity beziehen. Diese greift auf ein On-Prem System zu und liest dort einen Core Data Service ein. Diese Daten nehmen wir nun in unserer Anwendung auf und modellieren lokale Daten, die wir zum Datenmodell ergänzen wollen, hinzu. Darauf bauen wir dann ein gewisses Verhalten auf und abstrahieren das Ganze als Projektion, um eine Anwendung auf dem System zu erstellen. Hierbei handelt es sich um ein klassisches Erweiterungsszenario für eine Side-by-Side Anwendung.
Beispiel
Schauen wir uns in diesem Kapitel ein Szenario an, basierend auf einer External Entity, welches wir auf der ABAP-Environment zur Verfügung stellen.
Daten
Unsere Remotedaten kommen hier hauptsächlich aus der External Entity. Hierzu verwenden wir die gleiche External Entity, die wir auch für unseren Performance-Test verwendet haben. In der Entity gibt es entsprechende zufällige Daten, die wir anzeigen wollen. Dabei verzichten wir auf Informationen, wie zum Beispiel sehr große Textfelder oder andere zufällige Daten, die wir erst einmal ausblenden.
Modellierung
Bei der Modellierung müssen wir lokal unsere Zusatzdaten in einer Tabelle ablegen. Hier ergänzen wir auch die Felder, die wichtig sind für unser RAP-Objekt, um später mit Draft arbeiten zu können. Da wir diese Daten immer wieder wegschreiben, lohnt es sich, diese lokal vorzuhalten und dem Modell später zur Verfügung zu stellen.
@EndUserText.label : 'Additional Performance Data'
@AbapCatalog.enhancement.category : #NOT_EXTENSIBLE
@AbapCatalog.tableCategory : #TRANSPARENT
@AbapCatalog.deliveryClass : #A
@AbapCatalog.dataMaintenance : #RESTRICTED
define table zbs_hyb_perf_add {
key client : abap.clnt not null;
key identifier : abap.raw(16) not null;
line_comment : abap.char(160);
responsible : abap.char(12);
local_created_by : abp_creation_user;
local_created_at : abp_creation_tstmpl;
local_last_changed_by : abp_locinst_lastchange_user;
local_last_changed_at : abp_locinst_lastchange_tstmpl;
last_changed_at : abp_lastchange_tstmpl;
}
Auf der Tabelle modellieren wir einen Core Data Service. Diesen benötigen wir im zweiten Schritt für die gesamte Erstellung unseres Datenmodells. Grundsätzlich harmonisieren wir hier die Feldnamen und geben weitere semantische Informationen für die Draft-Felder vor. Ansonsten gibt es hier keine weiteren Besonderheiten.
@AccessControl.authorizationCheck: #NOT_REQUIRED
@EndUserText.label: 'Additional data'
define view entity ZBS_I_HYBPerformanceAdditional
as select from zbs_hyb_perf_add
{
key identifier as Identifier,
line_comment as LineComment,
responsible as ResponsiblePerson,
@Semantics.user.createdBy: true
local_created_by as LocalCreatedBy,
@Semantics.systemDateTime.createdAt: true
local_created_at as LocalCreatedAt,
@Semantics.user.localInstanceLastChangedBy: true
local_last_changed_by as LocalLastChangedBy,
@Semantics.systemDateTime.localInstanceLastChangedAt: true
local_last_changed_at as LocalLastChangedAt,
@Semantics.systemDateTime.lastChangedAt: true
last_changed_at as LastChangedAt
}
Dann können wir auch schon unser hybrides Szenario definieren. Dazu legen wir eine Root View an. Diese Root View selektiert von unserer External Entity und hat eine Assoziation zu unseren zusätzlichen Feldern. Diese zusätzlichen Felder binden wir dann auch direkt alle in unsere Entität ein.
@AccessControl.authorizationCheck: #NOT_REQUIRED
@EndUserText.label: 'Performance Data'
define root view entity ZBS_R_HYBPerformanceData
as select from ZBS_X_DemoSQLPerformance
association of one to one ZBS_I_HYBPerformanceAdditional as _Additional on _Additional.Identifier = $projection.Identifier
{
key Identifier,
ItemDescription,
RandomDescription,
Amount,
Currency,
NewDate,
NewTime,
_Additional.LineComment,
_Additional.ResponsiblePerson,
_Additional.LocalCreatedBy,
_Additional.LocalCreatedAt,
_Additional.LocalLastChangedBy,
_Additional.LocalLastChangedAt,
_Additional.LastChangedAt
}
Damit wäre die Modellierung schon abgeschlossen. Wir haben die externen Daten mit den lokalen Daten zusammengebracht und haben noch zusätzliche Informationen für die RAP-Laufzeit zur Verfügung gestellt.
Projection
Der Projection-Layer kann im Fall der External Entity dann ganz normal modelliert werden, es gibt keinerlei Einschränkungen, wie es auch beim klassischen RAP Objekt ist. Im Beispielmaterial findest du diesen Layer ebenfalls, wir haben ihn nur aus dem Artikel gelassen, da hier nichts spannendes passiert. Beim Szenario mit der Custom Entity, ist dies nicht möglich, da diese aktuell kein View-Stacking unterstützt.
Verhalten
Als Nächstes definieren wir das eigentliche Verhalten auf unserem RAP-Objekt. Dabei wollen wir mit Draft arbeiten, also aktivieren wir den Draft. Wir setzen die verschiedenen ETag-Felder, hier verwenden wir die lokalen Felder, die wir zur Verfügung stellen können. Im Datenmodell, da unsere Daten remote sind, gibt es eigentlich nur den Update-Fall. Und wir setzen den Create und den Delete auf INTERNAL, was für die Draft-Laufzeit wichtig ist. Die entsprechenden Felder aus der Remote Source setzen wir hier auf READONLY, da wir diese Inhalte sowieso nicht ändern können, zumindest nicht in unserem Fall. Wir ergänzen hier noch zusätzlich ein Mapping gegen unsere Tabelle, das wir dann später in unserer Implementierung auch wiederverwenden können. Wichtig ist hier vor allem der UNMANAGED SAVE, da wir nicht gegen eine echte Tabelle arbeiten, zumindest nicht mit den Hauptdaten, sondern gegen die Zusatztabelle, die wir manuell speichern müssen.
managed implementation in class zbp_bs_hybrid_performance unique;
strict ( 2 );
with draft;
define behavior for ZBS_R_HYBPerformanceData alias Performance
draft table zbs_hyp_draft
etag master LocalLastChangedAt
lock master total etag LastChangedAt
authorization master ( instance )
with unmanaged save
{
internal create;
update;
internal delete;
field ( readonly, numbering : managed ) Identifier;
field ( readonly )
ItemDescription,
RandomDescription,
Amount,
Currency,
NewDate,
NewTime;
draft action Edit;
draft action Activate optimized;
draft action Discard;
draft action Resume;
draft determine action Prepare;
mapping for zbs_hyb_perf_add
{
Identifier = identifier;
LineComment = line_comment;
ResponsiblePerson = responsible;
LastChangedAt = last_changed_at;
LocalCreatedAt = local_created_at;
LocalCreatedBy = local_created_by;
LocalLastChangedAt = local_last_changed_at;
LocalLastChangedBy = local_last_changed_by;
}
}
Nach der Implementierung müssen wir im ersten Schritt nur die SAVE_MODIFIED Methode anlegen. Hier wird es aber etwas tricky, da wir immer im Update-Fall sind, die Daten vielleicht aber gar nicht auf unserer Datenbank vorhanden sind. Daher ist eine vollständig Managed-Implementierung leider nicht möglich, da das System immer wieder versuchen würde, den Datensatz zu aktualisieren, auch wenn dieser nicht vorhanden ist, was zu einem Dump führt. In diesem Fall prüfen wir zuerst, ob der Datensatz vorhanden ist und lesen uns die Daten einmal aus. Dann gleichen wir die Daten, die wir im Update haben, mit den Daten von der Datenbank ab. Hier verwenden wir unser Mapping und die Control-Struktur. Am Ende führen wir ein MODIFY gegen die Datenbank aus, um die Daten entweder anzulegen oder zu aktualisieren. Grundsätzlich müssen wir sicher gehen, dass der Schlüssel immer gefüllt ist, da im Update Fall das Schlüsselfeld nicht verändert wird und damit, dank der CONTROL Struktur, nicht übernommen wird.
LOOP AT update-performance INTO DATA(update_performance).
SELECT SINGLE FROM zbs_hyb_perf_add
FIELDS *
WHERE identifier = @update_performance-Identifier
INTO @DATA(db_base).
DATA(modify_performance) = CORRESPONDING zbs_hyb_perf_add( BASE ( db_base ) update_performance MAPPING FROM ENTITY USING CONTROL ).
modify_performance-identifier = update_performance-Identifier.
MODIFY zbs_hyb_perf_add FROM @modify_performance.
ENDLOOP.
UI
Der Rest ist dann relativ RAP-Standard. Wir erzeugen noch die Projektionsschicht und genauso das entsprechende Verhalten auf dieser Ebene. Wir legen die Service-Definition an, sowie das Service-Binding, und publizieren den Service. Zum Abschluss generieren wir die Metadata Extension, um dem UI noch ein Aussehen zu geben. Hier verwenden wir unseren Metadata Wizard, ein kleines Open-Source-Projekt, das über eine IDE-Action implementiert wurde. Grundsätzlich kannst du die Metadata Extension auch manuell anlegen.

Test
Sind wir damit fertig, können wir auch noch einmal testen, ob unsere Anwendung nun sauber funktioniert. Dazu laden wir die Preview-Funktion und lassen uns im ersten Schritt die Anwendung einmal anzeigen und laden die ersten Daten, um zu sehen, ob die Verbindung überhaupt funktioniert.

Im zweiten Schritt editieren wir einen Datensatz und fügen einen kurzen Kommentar sowie ein Bearbeiterkürzel hinzu, damit wir die Informationen auf der Datenbank speichern und sie später zusammen mit dem Datensatz noch anzeigen können.

Eine Besonderheit, die wir vor allem mit der External Entity haben, ist, dass das Thema Filtering in unserer Anwendung sauber implementiert ist, ohne dass wir viel Aufwand haben, dieses manuell implementieren zu müssen. Machen wir also einmal einen Test über den Filter und filtern einmal nach dem Datum, das würde der Filter sein, der ins Backend (On-Prem) durchgereicht wird. Und wir geben einmal einen Filter ein von Werten, die lokal definiert sind, sodass wir beides einmal testen.
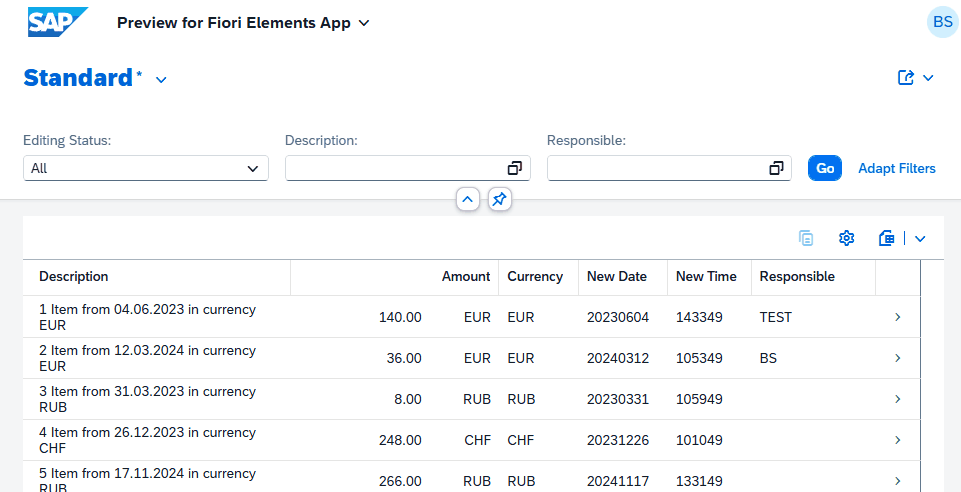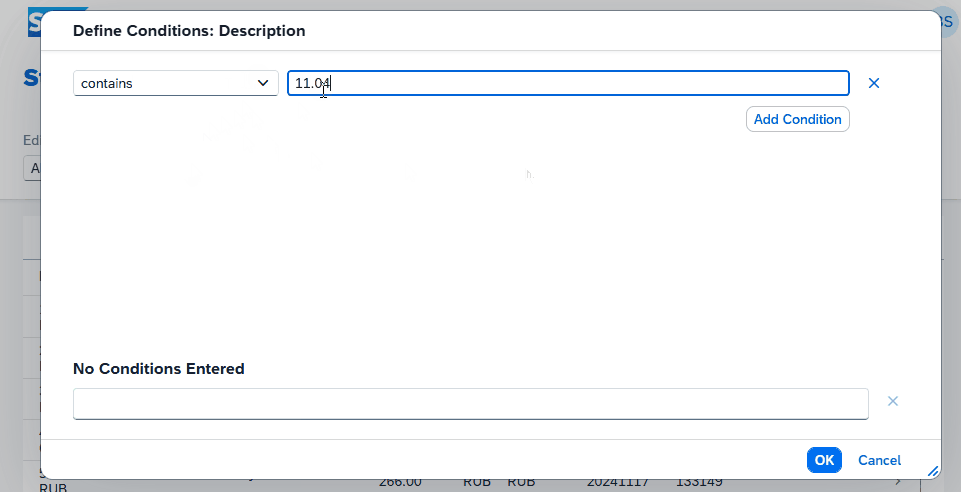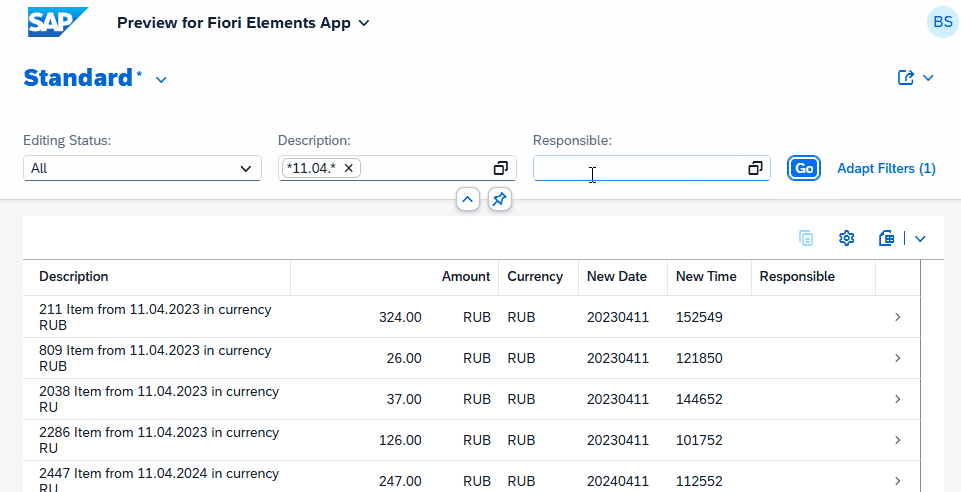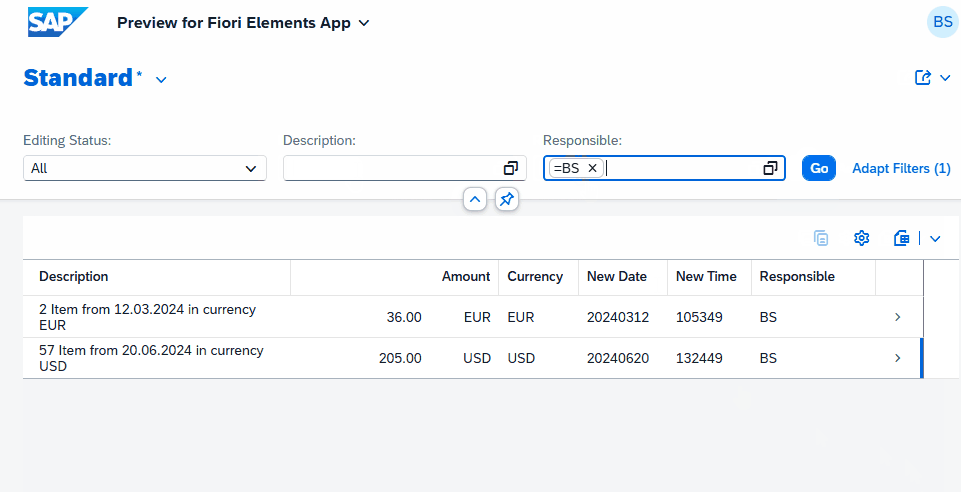
Die Interaktion mit dem UI, die du oben siehst, wurde in Echtzeit aufgenommen. Dies ist ein großer Vorteil, wenn wir mit External Entities arbeiten. Auch wenn die Daten hybrid sind, also zusammenmodelliert sind, können wir direkt sauber darüber filtern und erhalten schnell ein Ergebnis. Eine Implementierung per Custom Entity und dem manuellen Aufruf des OData-Services würde viel länger dauern und wäre nicht so performant. Weiterhin müssten wir sehr viel Logik implementieren, um den Filter auszusteuern, der gegen die verschiedenen Datenquellen läuft.
Vollständiges Beispiel
Das vollständige Beispiel zum aufgebauten Pattern, findest du im Paket ZBS_DEMO_RAP_PATTERN_HYBRID im GitHub Repository. Über den folgenden Commit siehst du alle Änderungen und Objekte, die ins Repository gekommen sind.
Zusammenfassung
Das Pattern wird hauptsächlich in der Side-by-Side-Entwicklung verwendet und beschreibt eigentlich nur, dass wir verschiedene Datenquellen aus verschiedenen Systemen zusammenführen und diese in einer Datenquelle zusammenbringen bzw. in einer Fiori-Anwendung. Dabei können wir bestimmen, welche Erweiterungen wir durchführen, ob wir zum Beispiel auch Remote-Funktionalitäten aufrufen, wenn der Anwender in unserer Anwendung eine Aktion ausführt.
Als Alternativszenario kann natürlich auch die Custom Entity verwendet werden. Dort würden die Daten über ein Consumption Model abgerufen werden können. Dies hat gewisse Nachteile, da wir hier einen viel höheren Aufwand haben, eine Implementierung vorzunehmen. Ebenfalls in der Anwendung gibt es gewisse Nachteile, da wir die Daten zusammen modellieren und anzeigen müssen. Auch das Thema Interaktion mit unserer Anwendung, das heißt, welche Felder werden angezeigt, welche Daten filtert der User im Frontend, müssten wir alles manuell berücksichtigen. Hier hat die External Entity sehr viele Vorteile und ist für uns ein wichtiger Punkt für die Erstellung von zukünftigen Anwendungen, die Side-by-Side gebaut werden sollen. Damit würde die Anzahl der möglichen Szenarien noch einmal steigen können.

Fazit
Aktuell werden Side-by-Side-Szenarien eher überschaubar gebaut. Dabei ist das Problem, dass vor allem beim Zugriff und die Modellierung der Backend-Daten sehr viel Aufwand nötig ist und es nicht unbedingt immer Synergien gibt, vor allem, wenn am Ende die Performance leidet. Hybride Entwicklung muss nicht kompliziert sein, sondern kann mit Hilfe der External Entities in Zukunft viel öfter umgesetzt werden, ohne viel Extra-Aufwand, sondern nur mit dem Aufwand der Konfiguration. Die eigentliche Modellierung kann dann nativ erfolgen, egal woher die Daten kommen.