DDIC der Zukunft (Morgen)
Wie geht es eigentlich mit dem DDIC in Zukunft weiter und können wir schon Heute die neuen Features für uns nutzen? In diesem Teil werfen wir ein Blick auf Morgen und wie uns CDS Artefakte bei der Modellierung helfen.

Inhaltsverzeichnis
In diesem Artikel werfen wir einen Blick auf die Zukunft und schauen uns Artefakte an, die wir in Zukunft für die Modellierung von Daten und Tabellen verwenden.
Einleitung
Schauen wir auf das Morgen, dann werden wir vor allem in einer Welt leben, die "CDS-only" heißt. Hierbei geht es darum, dass wir nur noch CDS-Artefakte nutzen und damit all die Vorteile, wie zum Beispiel die Groß- und Kleinschreibung oder längere Namen, aber auch ein integriertes Datenmodell, welches wir verwenden können, mitnehmen. Dabei werden die verschiedenen CDS-Objekte und auch neue Artefakte die bestehenden Artefakte ablösen und Alternativen bieten. Dabei ist die Alternative vor allem auf die Modernisierung und die neuen Anwendungen ausgelegt, die wir verwenden können. Dort werden andere Eigenschaften benötigt, als sie noch für die SAP-GUI vonnöten waren.
Gleichzeitig besteht nun eine große Chance, alte Fehler in der Datenmodellierung auszugleichen und neue Features einzuführen. Was in der Vergangenheit nicht möglich war und die Objekte nicht hergegeben haben, kann in der Zukunft durch neue Objekte möglich werden.
Übersicht
Werfen wir dazu einen ersten Blick auf die veränderte Landschaft der Objekte, die hier eine Rolle spielen. Grundsätzlich kann man sagen, dass alle Objekttypen einmal ausgetauscht und durch neue Typen ersetzt wurden. Im Bereich der Datenelemente und Domänen gibt es nun die Simple Types. Die Simple Types lösen damit zwei Elemente ab. Sie können ebenfalls gestapelt werden, das heißt, du kannst von den einzelnen Elementen Eigenschaften erben und diese weitergeben. Gleichzeitig bildet der Simple Type die unterste und die oberste Ebene ab. Statt Tabellen verwenden wir sogenannte Table Entities, die gleichzeitig die Struktur bieten, aber auch die Datenmodellierung und Persistenz für die Datenbank sicherstellen.
Auf der obersten Ebene verwenden wir Core Data Services, um Views abzubilden. Diese sind auch schon in der klassischen Welt mit Tabellen möglich, zur Vereinfachung hatten wir diese aber in dieses Modell übernommen. Darunter befindet sich ein neues Objekt, der sogenannte Aspect, ein Objekt, was wir uns in der Vergangenheit schon einmal angeschaut haben, um Wiederverwendbarkeit und Includes zu schaffen. Dafür gibt es jetzt kein Element, was genau eine Struktur abbildet, dafür kann man Abstract Entities verwenden. Diese werden vor allem im Bereich von Pop-ups und Strukturdefinitionen verwendet. Einzig der Tabellentyp hat aktuell noch kein Nachfolger. Hier ist auch die Frage, ob man unbedingt einen benötigt, vor allem, wenn man auf die Nutzung von Funktionsbausteinen schaut, die in der Zukunft immer weniger werden und durch OData-Services und HTTP-Schnittstellen abgelöst werden.
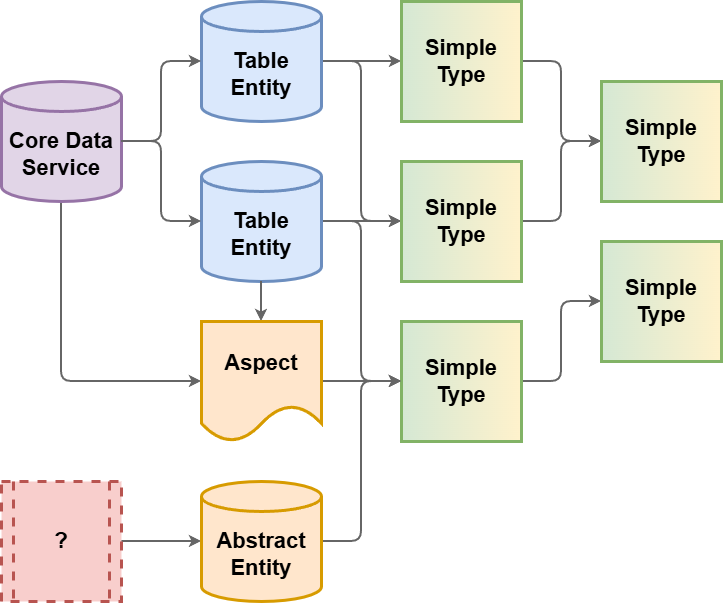
Elemente
Schauen wir uns die verschiedenen Objekte im Model einmal im Detail an und wie diese aufgebaut sind. Den Aspect im Zusammenspiel mit Table Entities haben wir uns in einem anderen Artikel bereits angeschaut.
Simple Type
Das Simple Type ist der eigentliche Datentyp, der als Element verwendet werden kann, um eine Spalte zu repräsentieren. Wir können darin verschiedene Texte definieren, den Namen des Objektes, aber auch den Datentyp. In diesem Fall verwenden wir einen eingebauten Datentyp. Hier können wir aber auch verschiedene andere Simple Types oder sogar Datenelemente verwenden, die wir zur Definition angeben. Damit ist die Definition relativ klein und schmal gehalten. Ein wichtiger Aspekt hierbei ist, dass wir Groß- und Kleinschreibung verwenden können, die auch später bei der Modellierung der Table Entity verwendet wird.
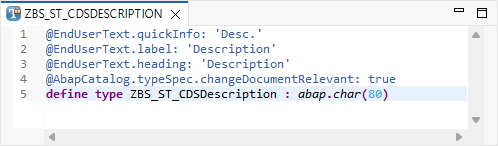
Möchtest du dazu noch Werte definieren, sogenannte konstante Werte? Dann steht dir auch die Ausprägung des Enums zur Verfügung. Hier definieren wir nach dem eigentlichen Typen noch verschiedene Werte, die für das Objekt zur Verfügung stehen, weisen den Konstanten Werte zu und können hier auch die Texte definieren, die vielleicht später für das UI von Relevanz sind. Weitere Eigenschaften können wir dann über Annotationen abbilden.

Table Entity
Die Table Entity ist die neue Form der Tabelle. Dabei haben wir wie in jedem CDS-Artefakt einen viel längeren Namen, den wir für die Tabelle vergeben können, ebenso können wir Groß- und Kleinschreibung verwenden. Auf den ersten Blick wird dir auffallen, dass das Client-Feld fehlt. Dies wird über eine Annotation im oberen Bereich abgebildet, ebenso wie die verschiedenen Eigenschaften der Tabelle. Auf Ebene der Tabelle können wir Felder definieren, die wiederum Simple Types als Basis haben, und wir können entsprechend die finalen Feldnamen vormodellieren, wie wir sie auch später im Modell verwenden. Wir können auch Annotationen für End-User-Labels verwenden oder Basistypen nutzen, wenn wir die Tabelle modellieren. Ein weiterer Vorteil ist, dass wir direkte Verbindungen über Assoziationen in der Table Entity aufbauen können. Damit bilden wir direkt auf Tabellenebene die Funktion ab und können die Beziehungen darstellen.
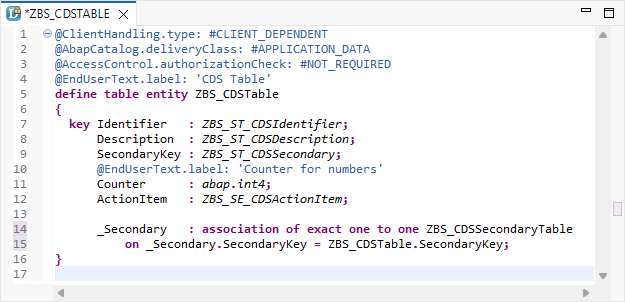
Auf Ebene der Tabelle können wir auch direkt ein Access Control anlegen, um unsere Tabelle und die Daten darin zu schützen. Damit wird Out-of-the-Box bei jedem Zugriff eine Berechtigungsabfrage durchgeführt, die dann validiert, ob der User überhaupt die Berechtigung hat, die Daten zu sehen.
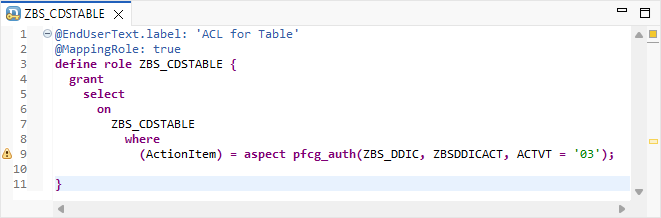
Neben den Assoziationen können wir auch Kompositionen und To-Parent-Beziehungen abbilden. Ebenso können wir eine Root Table Entity definieren. Das bedeutet, wir können auch mit diesen Artefakten direkt ein RAP-Objekt obendrauf modellieren und sparen uns die Zwischenschicht über Core Data Services, ebenso ein Mapping in der Verhaltensdefinition.
Abstract Entity
Ein weiterer Typ ist die Abstract Entity. Diese verhält sich ähnlich wie eine Struktur, das heißt, wir haben keine Daten, die dahinter gespeichert werden, und wir können auch keinen SELECT durchführen. Damit definieren wir einen Typen im System, der Felder bereitstellt. Hier können wir Datenelemente verwenden, wir können aber auch Simple Types oder eingebaute Datentypen verwenden, wenn wir die Struktur anlegen. Über eine Annotation haben wir die Möglichkeit, weitere Semantik zu ergänzen oder Texte, die wir später für das UI zur Verfügung stellen wollen.

Verwendung
Für die Verwendung schauen wir uns die beiden gleichen Beispiele an, wie wir sie bereits für das Datenmodell von heute machen, und schauen auf die Unterschiede.
Selektion
Der SELECT gegen die Table Entity sieht genauso aus wie der SELECT gegen eine Tabelle. Hier ändert sich erst einmal nichts für uns, wenn wir Daten lesen wollen. Der Vorteil der Table Entity ist hierbei, dass automatisch eine Berechtigungsprüfung durchgeführt wird. Das heißt, der ganze Boilerplate-Code, den wir beim Zugriff auf die klassische Tabelle benötigt haben, entfällt hier. Das spart dem Entwickler viel Implementierungsaufwand, und das Thema Security kann so auch nicht mehr vergessen werden.
SELECT FROM ZBS_CDSTable
FIELDS *
INTO TABLE @DATA(found_ddics).
Konstante
Auch der Zugriff auf Konstanten wird viel einfacher werden. In einem Beispiel definieren wir uns eine lokale Struktur über die abstrakte Entität, die wir vorher definiert haben. In der IF-Abfrage können wir dann direkt das Simple Enum verwenden und haben hier die Möglichkeit, auf den einzelnen Wert des Simple Enums zuzugreifen. Damit entfällt die Definition einer lokalen Klassenstruktur. Wir erhalten immer die aktuellen Werte, die im Enum definiert sind, und müssen nichts doppelt oder redundant pflegen.
DATA local_structure TYPE ZBS_S_CDSInformation.
IF local_structure-ActionItem = ZBS_SE_CDSActionItem-enhancement.
" TODO
ENDIF.
Vollständiges Beispiel
Alle erstellten Elemente und Beziehungen findest du in einem neuen GitHub Repository. Im Unterpaket ZBS_DEMO_DDIC_NEW findest du alle klassischen DDIC Elemente. Im Oberpaket haben wir übergreifende Elemente definiert, die wir verwenden.
Fazit
Das Modell von Morgen besteht nur noch aus "CDS-only"-Artefakten und bringt alle Vorteile mit die auch Core Data Services haben. Wir bekommen endlich längere Namen für die verschiedenen Objekte und können damit nativ Daten modellieren, die wir so an das Frontend weitergeben. Damit sparen wir uns verschiedene Schichten, die wir bisher definieren mussten,wie das Mappings von Feldern, und verschlanken somit auch die Modellierung in unseren Anwendungen.