RAP - API Pattern
In diesem Artikel schauen wir uns das API-Pattern für RAP an und wie du es flexibel in der ABAP Entwicklung einsetzen kannst, um Schnittstellen zur Verfügung zu stellen.

Inhaltsverzeichnis
In diesem Artikel schauen wir uns das API Pattern an, wie du es implementieren kannst und es sinnvoll in deine Entwicklung einbinden kannst.
Einleitung
Das ABAP RESTful Application Programming Model ist das neue Modell in ABAP, um Cloud Ready und Clean Core Anwendungen zu erstellen. Mit RAP lassen sich neben Anwendungen, auch Schnittstellen für den internen und externen Gebrauch zur Verfügung stellen. Mit den neusten Features ist RAP sehr flexibel was den Aufbau und die Nutzung angeht, weshalb wir die Anwendungen in verschiedene Pattern aufteilen möchten.
Aufbau
Das "API Pattern" dient zur Erstellung von Endpunkten zur Verarbeitung der Daten im System. Dabei verwenden wir den Standard des Modells wie die Struktur, Funktionen, Aktionen und Mapping, um die Daten für die Weiterverarbeitung vorzubereiten. Da wir in einem unmanaged Ansatz unterwegs sind, sind wir flexibel, was nach der Verarbeitung der Daten im System passiert. Für den Aufbau verwenden wir diese Legende:
Dazu die folgenden Merkmale zur Abgrenzung:
- Definition der Schnittstellen-Struktur über eine Custom Entity
- Nutzung des RAP Standards zur Validierung (Unmanaged)
- Kein Draft benötigt, daher OData v2
- Weiterverarbeitung innerhalb des Systems dynamisch
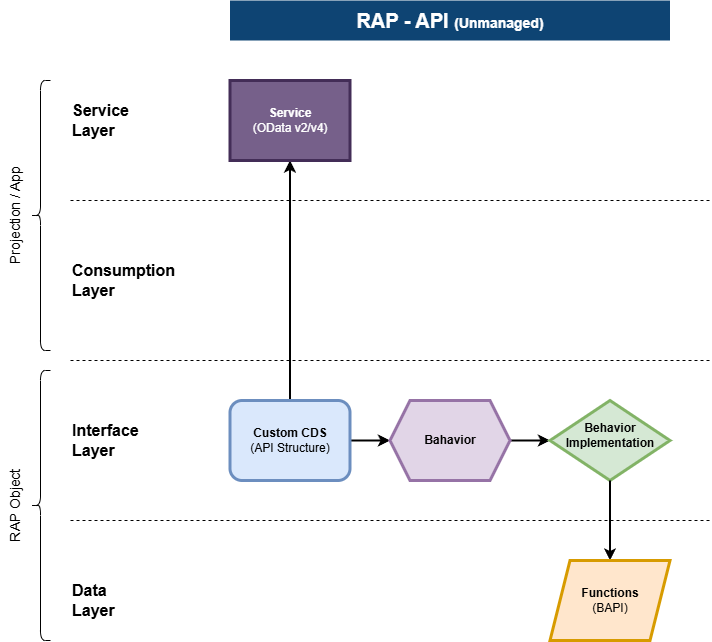
Das Modell ist relativ einfach aufgebaut, die Entität bildet die Eingangsstruktur für die Schnittstelle und das Verhalten nutzen wir zur Validierung und für die weiteren Schritte. Damit ist das RAP Objekt sehr einfach gehalten und kann flexibel weiterentwickelt werden.
Beispiel
Dazu erstellen wir einen API Endpunkt im System für verschiedene Standorte (Location), den wir über die Schnittstelle entgegennehmen wollen, prüfen und an die API zur Datenbank weiterleiten.
Service
Im ersten Schritt benötigen wir die Servicebeschreibung in Form einer Custom Entity. Damit definieren wir die Struktur der Schnittstelle für den Aufrufer und die Informationen, die wir benötigen. Eine Query Klasse für das Lesen benötigen wir nicht, da die Klasse nur Daten entgegen nimmt.
@EndUserText.label: 'Location API'
define root custom entity ZBS_R_APILocation
{
key LocationId : abap.char(15);
LocationName : abap.char(80);
LocationCoordinates : abap.char(35);
LocalPeople : abap.int4;
}
Darauf generieren wir uns eine Service Definition, um die Entität nach außen zu geben.
@EndUserText.label: 'Location API'
define service ZBS_API_LOCATION_ENDPOINT {
expose ZBS_R_APILocation as Location;
}
Damit wir den Service von außen her aufrufen können, legen wir uns ein Service Binding vom Typ Web-API an, hier reicht die Version OData v2, da wir kein Draft benötigen. Nach der Aktivierung und Freigabe, sollte uns der Endpunkt zur Verfügung stehen.
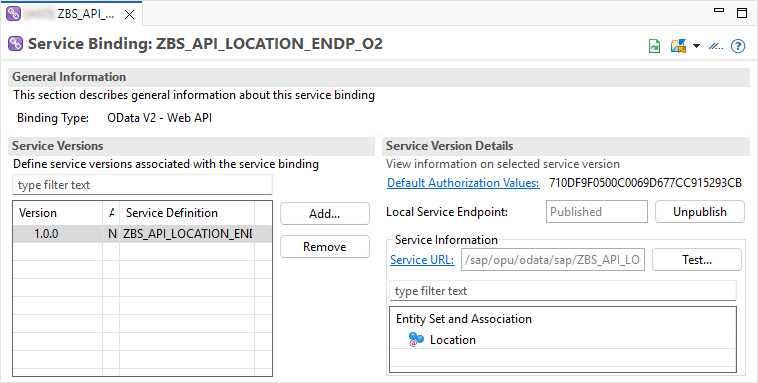
Verhalten
Mit bereits drei Objekten haben wir den Rumpf der Schnittstelle erstellt, nun benötigen wir aber noch ein Verhalten, um die Daten entgegenzunehmen und zu verarbeiten. Der Flow durch die Implementierung sieht wie folgt aus.
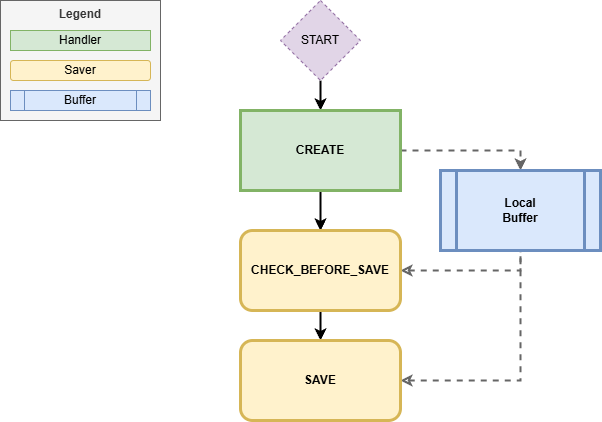
Dazu definieren wir die folgende Verhaltensdefinition im System. Die Definition ist unmanaged, da wir die Daten über einen anderen Weg weiterverarbeiten wollen. Grundsätzlich können wir STRICT(2) aktivieren, da wir uns an die RAP Regeln in der Verarbeitung halten werden. Da wir nur Datensätze anlegen wollen über die Schnittstelle, reicht uns der CREATE. Das Mapping legen wir an, da wir später die Eingangsdaten auf unsere Datenbank mappen möchten, wo wir die Daten zum Test persistieren.
unmanaged implementation in class zbp_bs_api_location unique;
strict ( 2 );
define behavior for ZBS_R_APILocation alias Location
lock master
authorization master ( instance )
{
create ( authorization : global );
field ( readonly : update ) LocationId;
mapping for zbs_api_target {
LocationId = location_id;
LocationName = location_name;
LocationCoordinates = location_coordinates;
LocalPeople = local_people;
}
}
Zum Abschluss lassen wir uns die leere Verhaltensimplementierung anlegen, wichtig sind für uns die Methoden CREATE, wo die Daten in die Verarbeitung kommen. In der Methode übernehmen wir die Daten in den Puffer, grundsätzlich könnten wir hier bereits Validierungen machen und Meldungen zurückgeben.
METHOD create.
INSERT LINES OF entities INTO TABLE lcl_buffer=>new_entries.
ENDMETHOD.
Wie üblich ist die Pufferklasse sehr einfach gehalten, um die Daten während der Verarbeitung zu halten.
CLASS lcl_buffer DEFINITION.
PUBLIC SECTION.
CLASS-DATA new_entries TYPE TABLE FOR CREATE zbs_r_apilocationlocation.
ENDCLASS.
Als nächsten Schritt wollen wir die Daten überprüfen, dazu verwenden wir die Methode CHECK_BEFORE_SAVE in der Saver-Klasse. An dieser Stelle ist die Interaktionsphase bereits abgeschlossen und wir haben alle Daten im Puffer, um sie zu validieren. Dabei gehen wir über alle Daten und prüfen die Location ID auf Korrektheit. Ebenfalls sollte die Einwohnerzahl größer als Null sein. Gibt es Fehler, dann können wir FAILED setzen und über REPORTED die Fehler an den Aufrufer geben.
METHOD check_before_save.
LOOP AT lcl_buffer=>new_entries INTO DATA(new).
IF NOT is_location_id_valid( new-LocationId ).
INSERT VALUE #( %key = new-%key ) INTO TABLE failed-location.
INSERT VALUE #( %key = new-%key
%msg = new_message( id = 'ZBS_DEMO_RAP_PATTERN'
number = '011'
severity = if_abap_behv_message=>severity-error
v1 = new-LocationId ) )
INTO TABLE reported-location.
ENDIF.
IF new-LocalPeople <= 0.
INSERT VALUE #( %key = new-%key ) INTO TABLE failed-location.
INSERT VALUE #( %key = new-%key
%msg = new_message( id = 'ZBS_DEMO_RAP_PATTERN'
number = '012'
severity = if_abap_behv_message=>severity-error ) )
INTO TABLE reported-location.
ENDIF.
ENDLOOP.
ENDMETHOD.
Im letzten Schritt wollen wir die Daten nun sichern oder weiterverarbeiten. An dieser Stelle könntest du nun einen BAPI, ein Standard RAP Objekt oder weitere Logik aufrufen. Wir mappen die Daten mit Hilfe des Mappings auf die Datenbank und übergeben sie an die lokale API, die sich um die Sicherung kümmert. Wenn dich die Implementierung interessiert, findest du die Klasse ebenfalls in Git.
METHOD save.
DATA(new_database_entries) = CORRESPONDING zcl_bs_api_target=>locations( lcl_buffer=>new_entries MAPPING FROM ENTITY ).
NEW zcl_bs_api_target( )->save_locations( new_database_entries ).
ENDMETHOD.
Damit ist die Implementierung der Schnittstelle abgeschlossen und wir können den Endpunkt nun testen.
Test
In diesem Kapitel testen wir den Endpunkt mit verschiedenen Szenarien und prüfen das Verhalten bei der Verarbeitung der Daten. Für unsere Tests verwenden wir den Postman, erklären hier aber nicht explizit, wie das Handling mit der URL oder dem x-csrf-token funktioniert. Mehr Informationen findest du in diesem Artikel.
Anlage (Fehler)
Testen wir im ersten Fall einmal die Validierung der Schnittstelle und senden falsche Daten an das Backend. Um mit der Anlage zu starten, benötigen wir einen POST und als JSON unsere entsprechenden Daten.
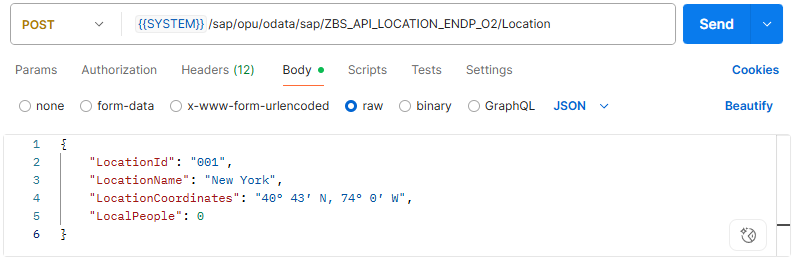
Hier findest du die Payload die wir für die Anlage verwenden.
{
"LocationId": "001",
"LocationName": "New York",
"LocationCoordinates": "40° 43′ N, 74° 0′ W",
"LocalPeople": 0
}
Als Antwort erhalten wir einen "Bad Request" ((Status 400). Wenn du das XML durchgehst, wirst du auch die beiden Fehlermeldungen finden. Die Einwohner sind null und die Location ID ist auch nicht korrekt. Damit funktioniert die Validierung auf RAP Seite.
<?xml version="1.0" encoding="utf-8"?>
<error xmlns="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata">
<code>ZBS_DEMO_RAP_PATTERN/012</code>
<message xml:lang="en">People must be greater than zero.</message>
<innererror>
<application>
<component_id/>
<service_namespace>/SAP/</service_namespace>
<service_id>ZBS_API_LOCATION_ENDP_O2</service_id>
<service_version>0001</service_version>
</application>
<transactionid>B2BD67F2A8D900B0E0068503E872AF7D</transactionid>
<timestamp>20250616193103.6384280</timestamp>
<Error_Resolution>
<SAP_Transaction>For backend administrators: use ADT feed reader "SAP Gateway Error Log" or run transaction /IWFND/ERROR_LOG on SAP Gateway hub system and search for entries with the timestamp above for more details</SAP_Transaction>
<SAP_Note>See SAP Note 1797736 for error analysis (https://service.sap.com/sap/support/notes/1797736)</SAP_Note>
</Error_Resolution>
<errordetails>
<errordetail>
<ContentID/>
<code>ZBS_DEMO_RAP_PATTERN/012</code>
<message>People must be greater than zero.</message>
<longtext_url>/sap/opu/odata/iwbep/message_text/T100_longtexts(MSGID='ZBS_DEMO_RAP_PATTERN',MSGNO='012',MESSAGE_V1='',MESSAGE_V2='',MESSAGE_V3='',MESSAGE_V4='')/$value</longtext_url>
<propertyref/>
<severity>error</severity>
<target/>
<transition>true</transition>
</errordetail>
<errordetail>
<ContentID/>
<code>ZBS_DEMO_RAP_PATTERN/011</code>
<message>LocationId 001 has the wrong format</message>
<longtext_url>/sap/opu/odata/iwbep/message_text/T100_longtexts(MSGID='ZBS_DEMO_RAP_PATTERN',MSGNO='011',MESSAGE_V1='001',MESSAGE_V2='',MESSAGE_V3='',MESSAGE_V4='')/$value</longtext_url>
<propertyref/>
<severity>error</severity>
<target/>
<transition>true</transition>
</errordetail>
</errordetails>
</innererror>
</error>
Hinweis: Durch das Befüllen der FAILED Informationen, wird in RAP intern ein ROLLBACK ausgelöst, damit werden keine Informationen gespeichert. Möchtest du ein Application Log speichern, um die Meldungen nachvollziehen zu können, musst du hier die zweite Datenbankverbindung nutzen.
Anlage (Einzel)
Nehmen wir im zweiten Schritt eine Payload die funktioniert. Die Location ID ist korrekt befüllt und es wurden Einwohner übergeben.
{
"LocationId": "L001",
"LocationName": "New York",
"LocationCoordinates": "40° 43′ N, 74° 0′ W",
"LocalPeople": 8804190
}
Führen wir die Verarbeitung aus, dann erhalten wir den Status "201 Created", damit ist die Verarbeitung durchlaufen. Prüfen wir nun die Tabelle ZBS_API_TARGET im System, dann wurde der Datensatz angelegt.

Anlage (Gruppe)
Mit dem Endpunkt können wir aktuell nur einzelne Datensätze anlegen, ein Anlegen von vielen Datensätzen funktioniert im Moment nicht. Hier können wir aber einen kleinen Trick verwenden und auf einen BATCH Request zurückgreifen. Hierbei handelt es sich um eine gesammelte Anfrage mit 1 bis n Operationen im Bauch. Dazu benötigt die Anfrage allerdings eine sehr spezielle Form und ist nicht immer einfach zu erstellen. Damit wir nun einen Batch-Request testen können, haben wir ein kleines Tool auf unserer Webseite erstellt, den OData Batch Creator. Dazu laden wir die Metadaten unseres Services in das Tool, diese werden benötigt, um die Entitäten und Strukturen zu kennen.
Über Aktion fügen wir nun die verschiedenen Aktionen hinzu, in unserem Fall wollen wir drei neue Datensätze anlegen, also benötigen wir drei Aktionen mit Create.

Wenn du dann auf "Refresh" drückst, wird die Payload im Fenster erzeugt und mit Dummy Daten befüllt, hier solltest du die Daten nach deinen Anforderungen befüllen. Die Struktur und Leerzeilen musst du beibehalten, da der Batch Request eine exakte Struktur benötigt.
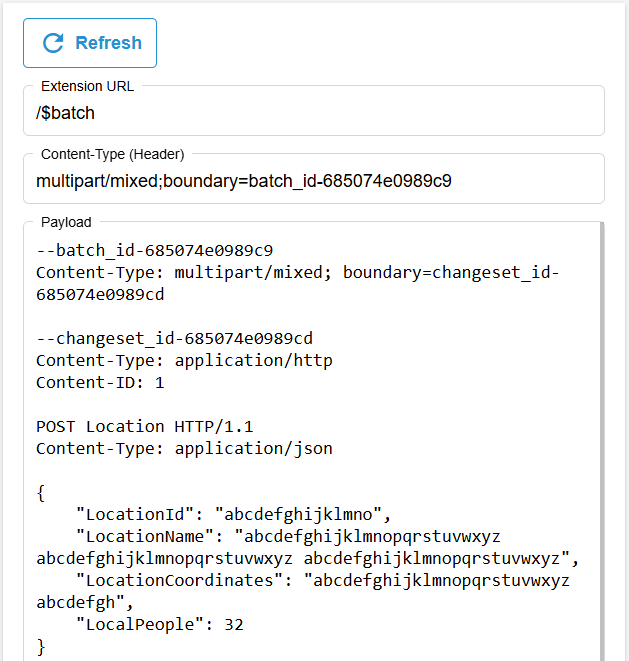
In unserem Fall sieht der Batch-Request wie folgt aus.
--batch_id-685066be96bf8
Content-Type: multipart/mixed; boundary=changeset_id-685066be96bfd
--changeset_id-685066be96bfd
Content-Type: application/http
Content-ID: 1
POST Location HTTP/1.1
Content-Type: application/json
{
"LocationId": "L001",
"LocationName": "New York",
"LocationCoordinates": "40° 43′ N, 74° 0′ W",
"LocalPeople": 8801234
}
--changeset_id-685066be96bfd
Content-Type: application/http
Content-ID: 2
POST Location HTTP/1.1
Content-Type: application/json
{
"LocationId": "L002",
"LocationName": "Paris",
"LocationCoordinates": "48° 51′ N , 2° 21′ O",
"LocalPeople": 2113705
}
--changeset_id-685066be96bfd
Content-Type: application/http
Content-ID: 3
POST Location HTTP/1.1
Content-Type: application/json
{
"LocationId": "L003",
"LocationName": "Pune",
"LocationCoordinates": "18° 31′ N, 73° 51′ O",
"LocalPeople": 3115431
}
--changeset_id-685066be96bfd--
--batch_id-685066be96bf8--
Bei einem Batch-Request ist wichtig, dass wir die URL und den Content-Type korrekt setzen. Anstatt der Entität, setzen wir nach dem Service $batch, um einen Batch Request zu definieren. In den Content-Type schreiben wir die Batch ID und geben ein Multipart Dokument an.

Führen wir nun den Batch aus, dann erhalten wir alle drei Datensätze auf einmal in der Verarbeitung und müssen die Daten nicht nacheinander abarbeiten. Dies macht vor allem Sinn, wenn wir ein Paket an Daten haben, die wir untereinander abgleichen müssen.

Wurde unser Datenpaket ohne Fehler angenommen, sollten wir ein "202 Accepted" erhalten und in der Payload noch einmal einen Batch mit dem Status jeder einzelnen Anfrage erhalten. Prüfen wir die Datenbank auf unsere Änderungen, dann wurden zwei neue Datensätze angelegt und ein Datensatz wurde aktualisiert.

Vollständiges Beispiel
Das vollständige Beispiel zum aufgebauten Pattern, findest du im Paket ZBS_DEMO_RAP_PATTERN_API im GitHub Repository. Über den folgenden Commit siehst du alle Änderungen und Objekte, die ins Repository gekommen sind.
Zusammenfassung
Das API Pattern stellt mit wenigen Mitteln einen flexiblen API Endpunkt zur Verfügung, der sich um das Thema Konsistenz und Fehlerbehandlung kümmert. Damit musst du nicht jede einzelne Funktion neu implementieren, sondern kannst auf dem RAP Framework aufsetzen. In unserem gezeigten Beispiel haben wir vor allem auf der Entität als Struktur aufgesetzt, es gibt aber auch immer noch die Möglichkeiten von Aktionen und Funktionen, damit kannst du zum Beispiel ganz einfach Deep Entities abbilden, wenn es sich um einen Eingangskanal für komplexe Strukturen, ähnlich wie bei Funktionsbausteinen, handeln soll.
Da wir bei dem Service kein UI verwenden, sparst du dir alle UI Annotationen und die Metadata Extension beim Aufbau der Schnittstelle. Ebenso lassen wir die Query Klasse weg, da die Schnittstelle keine Daten an den Aufrufer liefern soll.
Damit ist das Pattern recht schlank und übersichtlich bei der Entwicklung, bietet aber eine große Flexibilität bei der Annahme und Weiterverarbeitung der Daten innerhalb des Systems.
Fazit
Das API Pattern dient als einfacher Eingangskanal für die Ablage von Daten und die Weiterverarbeitung innerhalb des Systems. Im Rahmen des RAP Frameworks bekommst du einige Schritt und auch die Regeln geschenkt und kannst diese für eine saubere Implementierung nutzen.